NASD Architecture & Project Components
Network-attached, secure disk drives promise a revolutionary change
in disk-drive and file-system technologies, eliminating the server workstation
as the bottleneck from network and distributed file systems. Attaching
drives directly to networks allows direct client-drive communication
and makes the drive a fundamental building block of highly available,
high-performance, scalable, distributed storage. However, direct attachment
to a switched network mandates special measures to ensure the security
and integrity of data stored on the drive, as well as a drive interface
that obviates the need for requests and data to be routed through servers
in most cases.
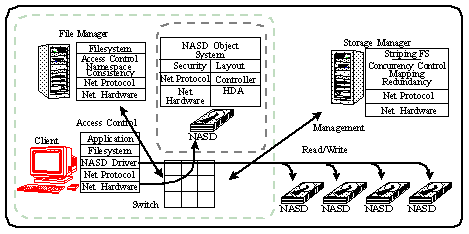
Figure 1: An overview of a scalable bandwidth NASD system. The major components are annotated with the layering of their logical components. The innermost box shows a basic NASD drive. The larger box contains the essentials for a NASD-based filesystem, which adds a file manager and client. Finally, the outer box adds a storage manager to coordinate drives on which parallel filesystem is built.
To realize the NASD technology's true potential, both efficiently and
cost effectively, significant changes in systems architecture are needed
to accomplish several things:
- avoid repeated store-and-forward copying of file segments through data "gateways,"
- limit data insecurity posed by large-scale and diverse organizational loyalties,
- counter the unacceptability of unavailability,
- exploit device-specific optimizations increasingly distanced from enabling applications by opaque software layers, and
- smooth interoperability discontinuities arising from slow
standardization efforts that are required to enable deployment of
the new technology.
Our approach, Network-Attached Secure Disks (NASD), comprehensively reduces access latency by:
- promoting devices to first-class network clients equipped with streamlined transfer protocols to eliminate intermediate copies and transfer with high bandwidth,
- exploiting at the device increasingly cost-effective computational power to offload device-specific optimizations, network access and storage management and to support availability and security services,
- restructuring the layering of file and storage systems software to enable offloading to devices and clients and to support diverse high-level file-system functionalities (distributed file systems vs. parallel file systems), and
- increasing the quality of workload information available at devices to improve self-management decisions and device specific optimizations.
To address these issues, the NASD project has been divided into five component sub-projects: (1) redesigning the interface between clients, file systems and storage; (2) incorporating a flexible security mechanism into storage; (3) developing appropriate hardware architectures for drive implementations; (4) ensuring efficient, cost-effective network protocols; and (5) exploiting storage processing with an embedded-video-service demonstration.
NASD Storage Interface Definition
We have finalized a definition for storage interface for Network-Attached Secure Disks (NASD). Broadly, network-attached secure disk interfaces should exhibit the following properties:
- Direct transfer: Data accessed by a filesystem client is transferred between the NASD drive and the client without indirection (store-and-forward) through a file server machine.
- Asynchronous filesystem oversight: frequently consulted but infrequently changed filesystem policy decisions, such as what operations a particular client can perform on a particular set of stored data, are made once by the file manager and asynchronously enforced by the NASD drive.
- Cryptographic support for request integrity: NASD drives must be capable of computing keyed digests on command and status fields without significant bandwidth penalty.
- Object-based interface: To allow drives direct knowledge of the relationships between disk blocks and to minimize security overhead, drives export variable length "objects" instead of fixed-size blocks. This also improves opportunities for storage self-management by extending into a disk an understanding of the relationships between blocks on the disk.
- Storage self-management: NASD drives should have knowledge of logical relationships between storage units and exploit these for transparent performance optimization and reliability assurance.
- Extensibility: NASD drives should be capable of offering extensions for specific, demanding client applications without requiring modification of file manager software.
Additionally, NASD drives should offer cryptographic support for high-performance data integrity, data privacy and command privacy.
Objects are created, deleted, named, allocated and copied at the drive.
The choice of drives managing variable-length objects instead of storing
fixed-length, fixed-location blocks is driven by the need to authorize
access to specific data and by the observation that advanced storage
systems achieve performance and capacity optimizations by remapping
the block address.
NASD Security Protocol
We have developed a capability-based NASD security protocol enabling asynchronous verification of outstanding policy decisions. This protocol also allows a NASD drive to be independent of the specifics of its environment's authentication and access control systems. Moreover, the drive's long-term secure state is limited to a secret key hierarchy for each partition.
Briefly, a file manager agreeing to a client's access request privately
sends a token and a key to the client, which together form an object
capability. Client requests on a NASD drive contain the capability token
and are digested with the capability key. The drive, using the object's
secret key, constructs the implied capability key as a function of a
request's capability token and verifies the request's digest. Agreement
of delivered and computed digests assures the drive that the capability
token is authentic and the request's composer holds the corresponding
capability key. Revocation exploits the object version and rights expiration
time fields of each capability token. For example, immediate revocation
is implemented by directly modifying the object's version attribute
on the drive.
File Systems for NASD
NASD drives attached to clients by a high-bandwidth switched network are capable of scalable aggregate bandwidth. However, most client applications do not access data directly - they access data through higher-level distributed filesystems. To demonstrate the feasibility of NASD, we have ported two popular distributed filesystems, NFS and AFS, to our NASD environment. We have also implemented a minimal distributed filesystem structure that passes the scalable bandwidth of network-attached storage on to applications. To scale achievable bandwidth with increasing storage capacity, however, requires more than simply attaching storage to the network. For example, even if the application issues sufficiently large requests, NFS and AFS break these requests into small transfer units and limit the number of requests that are concurrently issued to storage.
NASD/NFS
Version 3 of the NFS distributed filesystem has been adapted to use our prototype NASD interface. Encoding NASD drive and object naming in NFS' file handle and piggybacking capability acquisition on NFS pathname component lookup operations, modifications to NFS client code are simple and localized. File read, file write and attribute read operations are redirected directly to the NASD drive. Our initial implementation's performance is within 10% of the native NFS for a single run of the Andrew benchmark and scales the number of active clients and drives much more effectively than native NFS because NASD-NFS file manager load is much less than native NFS. Using the Andrew benchmark [Howard88] as a basis for comparison, we found that NASD-NFS and NFS had benchmark times within 5% of each other for configurations with 1 drive/1 client and 8 drives/8 clients. In our experiments with these prototypes, we have demonstrated that NASD based systems experience scalable bandwidth where the original SAD file servers with direct-attached SCSI drives do not. Notably, aggregate transfer bandwidth was 20 to 90% higher for NASD than for traditional systems over a set of benchmark tests.
NASD/AFS
Version 3.4 of the AFS distributed filesystem has also been adapted to use our NASD prototype. Encoding is similar to NFS on NASD, but AFS allows clients to parse directories directly, so new file manager interfaces were added to explicitly obtain capabilities. AFS's cache consistency and quota features make it a more interesting implementation; client writes are batched and each batch obtains a capability immediately before writing and retires that capability immediately after writing. By retiring a write capability before continuing the application, AFS ensures that the file manager can break callbacks on other caching clients. Our AFS implementation uses outstanding capabilities in a similar manner for escrowing quota into writable objects. Initial performance, as for our NFS port, is within 10% of the execution time of native AFS for the Andrew benchmark and delivers scalable bandwidth without increase in client execution time as the number of active client-drive pairs increase (up to 4 in these tests).
Striped NASD (Cheops)
We have developed a user-level NFS client able to issue large data accesses into files striped over multiple disks (not supported by NFS or AFS). Rather than modify the NFS server to understand disk striping, we used the NASD-NFS file manager built for the basic NFS port to NASD and added a logical object manager. Clients obtaining a capability from the NFS-NASD file manager will send their first access to the logical object manager which will return a map of the striped objects containing NASDs and the appropriate list of capabilities. Later accesses will bypass both NASD-NFS file manager and logical object manager. In scalability tests in which large read access are issued at random offsets in large files, striped NASD-NFS clients achieved linear agreggate bandwidth on up to four client-drive pairs while native NFS on striped (logical volume manager) disks saturate at 66% of the striped NASD-NFS bandwidth.
While aggregate bandwidth scales with NASD based NFS and AFS ports,
the bandwidth to one file can only scale if files are striped over
multiple NASD drives. The Cheops storage service does this striping.
With Cheops, the file manager is left unmodified and Cheops provides
two new entities, a striping manager and client clerk. The striping
manager acts like a virtual NASD drive, allowing the file manager
to be ignorant of the striping and handling the allocation of striped
files and the construction of capabilities enabling access to objects
on the virtual drives. Files are accessed by the client through the
client clerk which has previously contacted the striping manager to
obtain the virtual NASD to physical NASDs mapping and can issue requests
for the files to the appropriate physical NASD. In a large read benchmark
experiment using this Cheops design, the aggregate bandwidth of a
single file being read by several clients concurrently scales nearly
linearly.
NASD Extensions
Prefetching
Our storage-embedded informed prefetching system acts collaboratively with I/O-intensive applications and is independent of and transparent to the NASD-NFS file manager owning the prefetching storage. It demonstrates a 40% reduction in elapsed time for out-of-core planar visualization of 3D scientific data striped over three drives and managed by a NASD storage subsystem extended with informed prefetching. The ability to extend intelligent drives for specific applications without modifying operating system and file manager code is essential for a nimble, customer-oriented storage marketplace.
To demonstrate the value of NASD drive extensions, we added an informed prefetching system to a NASD drive and an associated NASD/NFS client. Applications issue hints to the drives to describe their future read accesses. NASD drives then prefetch the data to the drive cache, making it available to the client on demand without a physical disk access. Evaluating the performance of this system using XDataSlice proved that prefetching over a NASD drive provided a speedup of 1.76 over the non-hinted run.
NASD Video
We have developed a reservation protocol for a decentralized, scalable
video server using internet RSVP/RTP/RTSP protocols. We have implemented
the reservation system in a decentralized video server and adapted the
Informedia digital library client interface running under Windows NT
to use the reservation protocol. Movies are striped across NASD drives,
pulled into a merging server and delivered to clients via RTSP (Real
Time Streaming control Protocol).
Networking Interface
The success of a NASD architecture for scalable storage systems depends on its networking environment. Current networking technology, however, does not provide a clear solution for network-attached storage. FibreChannel is the front-runner, but the emergence of System Area Networks (SANs) is a compelling solution, potentially enabling us to wire-once and share the physical network between servers, clients, and storage.
Regardless of the networking technology, we believe there are several factors that are critical to the success of network-attached storage. For example, it is essential that the network enable a thin protocol stack. Storage's current high-performance standard, the SCSI peripheral interconnect, provides credit-based flow control and reliable in-order delivery, enabling a thin network stack that minimizes host processing. Network-attached storage must provide the same level of efficiency when client and storage share a link-level medium.
Of equal importance is efficient, low-latency, small messaging that supports distributed file systems' small message traffic. Network protocols that impose significant connection overhead and long codepaths will be a primary determinant in cached storage response time and file manager scalability. Finally, there must be a clear network media winner. One possible solution is the wide-spread adoption of the cluster SAN. Based on commodity interconnection networks and by employing protocols optimized for high-bandwidth and low-latency, SANs are a natural fit for scalable storage. Network-attached storage could also target commodity LANs (e.g., ethernet). Unfortunately, the common LAN internet protocol suite is a less effective match for storage. However, a workgroup LAN that employs a cluster SAN as its LAN allows storage and clients to use the same media and link-layers. This increases its commodity advantages while providing appropriately thin protocols and support for small messages within the LAN and employing a protocol converter for remote accesses outside of the LAN.
The actual choice of networking remains unclear. Storage implementors
certainly favor FibreChannel since it is already being implemented in
storage subsystems and drives. However, another widely understood, more
cost-effective SAN that enables a thin-protocol and provides reliability
might displace FibreChannel, allowing us to wire-once and share the
physical network between clients and storage.
Active Disks
Recent work has focused on the next step in exploiting the growing availability of on-drive computation by providing full application-level programmability to the drives in what we call Active Disks. These next generation storage devices provide an execution environment directly at individual drives and allow code to execute near the data and before it is placed on the interconnect network. This gives the operator the ability to customize functionality for specific data-intensive applications. By extending the object notion of the basic NASD interface to include code that provides specialized "methods" for accessing and operating particular data types, there is a natural way to tie computation to the data and scale as capacity is added to the system. This type of extension functionality is available for the first time because NASD's object-based interface provides sufficient knowledge of the data at the individual devices without having to resort to external metadata.
Applications such as data mining and multimedia have been explored
for use in Active Disks. One of the applications examined is the frequent
sets computation discussed above. In our experiments, sales transaction
data was distributed across a set of drives. Instead of reading the
data across the network into a set of clients to do the itemset counting,
the core frequent sets counting code is executed directly inside the
individual drives. This takes advantage of the excess computational
power available at the drives and completely eliminates the need for
the client nodes in this application. Using the same prototype NASD
drives and approximate Active Disks functionality, 45MB/s with low-bandwidth
10Mb/s ethernet networking with only 1/3 of the hardware used in the
NASD PFS tests was achieved.
Extreme NASD
We have implemented on Linux and are releasing a prototype of the NASD drive software (including security), a file manager and client for our prototype filesystem, which we call EDRFS, and a prototype of the Cheops storage manager. Some configuration and management tools for the NASD drive and EDRFS filesystem are also included.
The prototype code as a whole is easily ported. At this time the drive and file manager all run as user processes on Linux, Digital UNIX 3.2G, IRIX, and Solaris. In addition, the Digital UNIX port can run the drive and file manager inside the kernel.
On Linux, both the drive and EDRFS file manager can be executed as either a user process or as a loadable kernel module (LKM). Other modules are primarily implemented as user processes, although the EDRFS client is available only as a LKM. Because NASD is intended to directly manage drive hardware, our NASD object system implements its own internal object access, cache, and disk space management modules and interacts minimally with its host operating system.
For communication, our prototype uses either a customized TCP-based RPC (SRPC) or DCE RPC over UDP/IP. The DCE implementation of these networking services is quite heavyweight, and is not available inside the Linux kernel. The appropriate protocol suite and implementation is currently an issue of active research.