Inter-job Dependency-aware Data Lake Scheduling
Inter-job dependencies pervade shared data analytics infrastructures (so called "data lakes"), as batch analytics jobs read output files written by previous jobs, yet are invisible to current cluster schedulers. Often, jobs are submitted one-by-one, without indicating dependencies, and the scheduler considers them independently based on priority, fairness, etc. Our analysis on hidden inter-job dependencies in a large-scale production Cosmos cluster at Microsoft, based on job and data provenance logs, find that nearly 80% of all batch analytics jobs depend on the output of at least one other job. Yet, even in an expertly-managed and business-critical setting, we see jobs that fail because they depend on not-yet-completed jobs, jobs that depend on jobs of lower priority, and other difficulties with hidden inter-job dependencies.
|
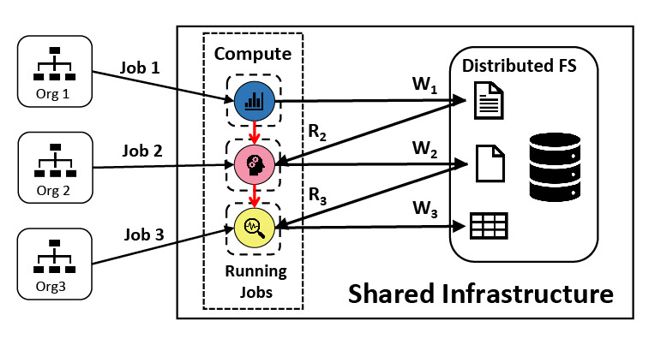
A canonical data lake: Different types of applications, submitted by different organizations, share the same compute infrastructure and read (R) and write (W) to the same storage system, thereby creating inter-job dependencies as jobs consume the output of other jobs. For example, Job 2 (from Org 2) reads a file written by Job 1, so Job 2 depends on Job 1. |
Our analysis finds that up to 68% of jobs in the analyzed cluster exhibit their dependencies in a recurring fashion, demonstrating the predictability of inter-job dependencies in a large fraction of jobs. This project exploits the recurrence of inter-job dependencies, and builds (1) tools for finding and characterizing hidden inter-job dependencies and (2) new resource management systems that utilize awareness of inter-job dependencies to better value/prioritize jobs and scheduler resources.
People
FACULTY
GRAD STUDENTS
INDUSTRY COLLABORATORS
Carlo Curino (Microsoft)
Subru Krishnan (Microsoft)
Konstantinos Karanasos (Microsoft)
Panagiotis Garefalakis (Cloudera)
Publications
- Unearthing Inter-job Dependencies for Better Cluster Scheduling. Andrew Chung, Subru Krishnan, Konstantinos Karanasos, Carlo Curino, Gregory R. Ganger. 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI'20), Virtual Event, Nov. 4–6, 2020.
Abstract / PDF [1.0M] / Slides / Talk Video
- Peering through the Dark: An Owl’s View of Inter-job Dependencies and Jobs’ Impact in Shared Clusters. Andrew Chung, Carlo Curino, Subru Krishnan, Konstantinos Karanasos, Panagiotis Garefalakis, Gregory R. Ganger. SIGMOD ’19, June 30–July 5, 2019, Amsterdam, Netherlands. Abstract / PDF [1.6M]
Acknowledgements
We thank the members and companies of the PDL Consortium: Bloomberg LP, Everpure, Google, Jane Street, LayerZero Labs, Meta, Microsoft Research, Oracle Corporation, Salesforce, Uber, and Western Digital for their interest, insights, feedback, and support.