efficient and scalable cache eviction with lazy promotion and quick demotion
The cache eviction algorithm is the heart of a cache. The effectiveness and performance of the eviction algorithm decide the efficiency, throughput, and scalability of a cache. This project aims to design simple, efficient, and scalable cache eviction algorithms.
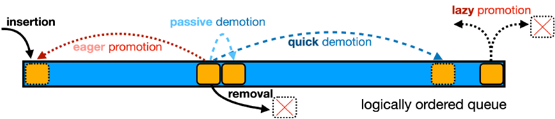
A cache can be viewed as a logically ordered queue with four operations — insertion, removal, promotion, and demotion. Among them, promotion and demotion are internal operations used to maintain the ordering of objects in the queue. Through a large-scale workload study and cache simulations on over 6000 traces collected from 2007 to 2023, we make two observations. First, we find that Lazy Promotion — promotion only at eviction, such as reinsertion in FIFO-Reinsertion/CLOCK, not only improves throughput and scalability but also improves efficiency. While conventional wisdom suggests FIFO-Reinsertion/CLOCK is a weak LRU, we find it is more efficient than LRU. Second, we find Quick Demotion — removing most new objects quickly is the key to efficient cache eviction algorithms. The eviction algorithms that can perform quick demotion are often more efficient.
PEOPLE
FACULTY
GRADUATE STUDENTS
COLLABORATORS
Yazhuo Zhang (Emory University)
Yao Yue (ex-Twitter)
Publications
- SIEVE is Simpler than LRU: An Efficient Turn-Key Eviction Algorithm for Web Caches. Yazhuo Zhang, Juncheng Yang, Yao Yue, Ymir Vigfusson, K. V. Rashmi. 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI'24), April 16–18, 2024. Santa Clara, CA.
Abstract / PDF [1M]
- FIFO Queues Are All You Need for Cache Eviction. Juncheng Yang, Yazhuo Zhang, Ziyue Qiu, Yao Yue, Rashmi Vinayak SOSP '23: Proceedings of the 29th Symposium on Operating Systems Principles, October 2023. Koblenz, Germany.
Abstract / PDF [1.6M]
- FIFO Can Be Better than LRU: The Power of Lazy Promotion and Quick Demotion. Juncheng Yang, Ziyue Qiu, Yazhuo Zhang*, Yao Yue^, K. V. Rashmi. HotOS ’23, June 22–24, 2023, Providence, RI, USA.
Abstract / PDF [1.2M]
Code
- A large collection of cache traces:
https://ftp.pdl.cmu.edu/pub/datasets/twemcacheWorkload/cacheDatasets
- A high-performance cache simulator:
https://github.com/1a1a11a/libCacheSim
Acknowledgements
We thank Twitter for allowing us to investigate the performance of production caches and open-source the large cache trace dataset. The project is supported by a Facebook Fellowship, NSF CNS 1901410 and 1956271. The computation was performed on the PDL clusters, the Cloudlab testbed, the Chameleon testbed, and AWS.
We thank the members and companies of the PDL Consortium: Bloomberg LP, Everpure, Google, Jane Street, LayerZero Labs, Meta, Microsoft Research, Oracle Corporation, Salesforce, Uber, and Western Digital for their interest, insights, feedback, and support.