Caching to Improve Latency and Efficiency at Scale (CILES)
Our interactive world of computing, requires fast response times as well as energy and cost efficiency. Caching is a key component to achieving these goals in web-services, analytics, and storage applications. The growth of cache deployments at every layer has exposed gaps between existing assumptions as well as heuristics and practical requirements. The CILES project aims to develop experimental prototypes, which improve the tail latency and efficiency of large deployments, and analytical models, which enable us to efficiently explore the massive design space of caching systems.
MACHINE LEARNING FOR CACHING
Baleen: ML Admission & Prefetching for Flash Caches:
Baleen is a flash cache for bulk storage systems that uses machine learning to train admission and prefetching policies to reduce peak backend load. It does this by introducing a new cache residency model (episodes) to guide model training, and by optimizing for an end-to-end system metric (Disk-head Time) that measures backend load for variable-size workloads more accurately than IO miss rate or byte miss rate. We also introduced OPT, an approximate offline optimal flash admission policy that is based on episodes. To our knowledge, Baleen is the first cache that optimizes peak disk-head time.
PDF / Code / Traces
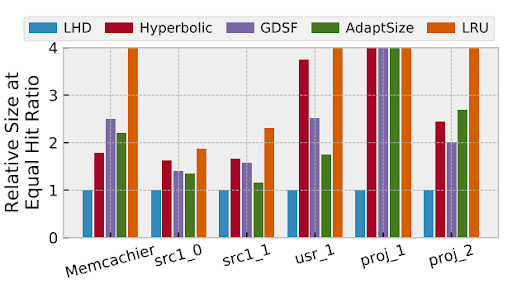
Robust Caching Policies that Reduce DRAM Cache Sizes
AdaptSize and LHD are the first caching systems that use online models to adapt the cache eviction with the request traffic, while achieving the high throughput requirements of DRAM caches.
AdaptSize is motivated by the variable workloads at the edge of the Internet, in large content delivery networks. It’s model enables it to efficiently explore the parameter space of CDN DRAM caches. This way, AdaptSize can react to the frequent changes in traffic patterns within seconds and proves robust even under adversarial attacks, which are more common at the edge.
LHD is motivated by complex workloads in storage systems, e.g., due to applications that loop over data. By tracking reuse probability distributions on a per-application basis, LHD is able to accurately predict which objects will take longer to get their next access. By evicting such objects, which waste cache space (i.e., have the least hit density), LHD requires much less cache space to achieve the same hit ratio as heuristical policies such as LRU.
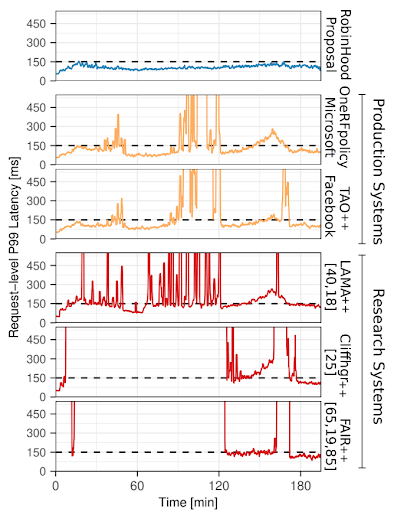
Using Cache to Improve Tail Latencies
A widely-held opinion is that “caching layers . . . do not directly address tail latency, aside from configurations where it is guaranteed that the entire working set of an application can reside in a cache” [The Tail at Scale]. Yet, tail latency is of great importance in user-facing web services. We analyze a Microsoft production system and find that backend query latencies vary by more than two orders of magnitude across backends and over time, resulting in high request tail latencies.
We overcome the widely-held opinion by building RobinHood, an experimental caching system that effectively reduces tail latency. RobinHood dynamically reallocates cache resources backends which don’t affect tail latency backends which currently cause tail latency. This enables us to hide to reduce load on high-latency backends and hide their high latency. We evaluate RobinHood with production traces on a 50-server cluster with 20 different backend systems. RobinHood meets a 150ms P99 goal 99.7% of the time, whereas the next best policy meets this goal only 70% of the time.
Replacing DRAM with New Generations of Flash Caches
Flash is 10x cheaper and 20-100x more power efficient than DRAM. However, caching on flash comes with its own set of challenges. First and foremost is the limited write endurance of flash cells, which is exacerbated non-sequential writes common in caching. Without limiting the continuous write rate of caches at large companies, flash caches cannot achieve their planned device lifespans by exhausting the endurance of flash cells. This is particularly important for scenarios with high churn rates such as social networks and CDNs, where the contents of the cache is continually changing.
We aim to address this challenge from two angles. First, we need to use admission policies, which prevent objects, which are likely to receive few hits, from ever being written to flash. While this approach has been recognized in prior work, we find that existing admission policies are not effective in practice. In collaboration with engineers at Facebook, we have developed an machine-learning-based admission policy, which effectively maps the per-objects features available in different applications to admission decisions. This way, we can lower write rates by 75% without sacrificing the flash cache’s hit ratio.
Our second research angle is to improve flash cache designs to result in fewer writes and amplification in the first place. This is challenging because cache misses occur for random objects and because these objects have highly variable sizes. While allocating these objects in a more sequential pattern on flash sounds promising, we would then need to track each object’s position on flash in DRAM to enable fast lookups. Due to the frequency of very small objects, this would require excessive amounts of DRAM, effectively negating the advantage of caching on flash. We are prototyping new ideas based on ideas from computer architecture to overcome this limitation.
Workload Analysis and Modeling
One of the current targets of CILES is the characterization of the diversity in caching workloads and its impact on cache design. Did you know that there are few public workload traces and that hundreds of papers rely on a simple theoretical model, called the Zipf distribution, to evaluate their caching designs? Due to the scarcity of other data sources, existing caching research has started to overfit to the few public traces and the Zipf distribution. We find that the majority of production traces at major companies are neither similar to existing public traces nor fit the Zipf popularity model. For example, the proposal for tiny in-network caches [NetCache, SOSP’17] assumes that 1MB of cache space can achieve a 40% hit ratio. In contrast, we find that 1MB achieves less than 0.5% hit ratio in practice and that in-network caches have to be several magnitudes larger in practice.
The CILES project aims to develop a workload model that is general enough to capture key characteristics of caching workloads. We hope that this workload model can be widely shared among researchers to ensure that our design can be more readily translated into practice.
NEWS
September 2, 2021: Facebook's CacheLib project is live.
People
FACULTY
Nathan Beckmann
Greg Ganger
Mor Harchol-Balter
Rashmi Vinayak
GRAD STUDENTS
Benjamin Berg
Isaac Grosof
Sara McAllister
Charles McGuffey
Nirav Natre
Brian Schwedock
Jason Yang
Daniel Wong
INDUSTRY COLLABORATORS
Akamai: Ramesh Sitaraman
Facebook: Sathya Gunasekar, Jimmy Lu, Hao Wu
Google / Youtube: Pawel Jurczyk
Google: Carlos Villavieja, David Bacon
Microsoft: Daniel S. Berger
Two Sigma: Joshua Leners, Larry Rudolph
Publications
- Baleen: ML Admission & Prefetching for Flash Caches. Daniel Lin-Kit Wong, Hao Wu, Carson Molder, Sathya Gunasekar, Jimmy Lu, Snehal Khandkar, Abhinav Sharma, Daniel S. Berger, Nathan Beckmann, Gregory R. Ganger. 22nd USENIX Conference on File and Storage Technologies (FAST'24), Feb. 27–29, 2024, Santa Clara, CA.
Abstract / PDF [2.7M] / Code / Traces
- GL-Cache: Group-level Learning for Efficient and High-performance Caching. Juncheng Yang, Ziming Mao, Yao Yue, K. V. Rashmi. 21st USENIX Conference on File and Storage Technologies (FAST '23). Feb. 21–23, 2023, Santa Clara, CA.
Abstract / PDF [1.84M]
- C2DN: How to Harness Erasure Codes at the Edge for Efficient Content Delivery. Juncheng Yang, Anirudh Sabnis, Daniel S. Berger, K. V. Rashmi, Ramesh K. Sitaraman. 19th USENIX Symposium on Networked Systems Design and Implementation. April 4–6, 2022 • Renton, WA, USA.
Abstract / PDF [1.9M] / Slides / Talk Video
- Kangaroo: Caching Billions of Tiny Objects on Flash. Sara McAllister, Benjamin Berg, Julian Tutuncu-Macias, Juncheng Yang, Sathya Gunasekar, Jimmy Lu, Daniel Berger, Nathan Beckmann, Gregory R. Ganger. Proceedings of the 28th ACM Symposium on Operating Systems Principles (SOSP '21) October 25-28, 2021. Virtual Event. BEST PAPER AT SOSP'21!
Abstract / PDF [7.8M] / Talk Video-Short / Talk Video-Long / Blog Post
- Segcache: A Memory-efficient and Scalable In-memory Key-value Cache for Small Objects. Juncheng Yang, Yao Yue, K. V. Rashmi. 18th USENIX Symposium on Networked Systems Design and Implementation (NSDI). Virtual Event, April 12–14, 2021. NSDI'21 Community Award and NSDI'21 BEST PAPER AWARD!
Abstract / PDF [517K] / Slides / Talk Video
- The CacheLib Caching Engine: Design and Experiences at Scale. Benjamin Berg, Daniel S. Berger, Sara McAllister, Isaac Grosof, Sathya Gunasekar, Jimmy Lu, Michael Uhlar, Jim Carrig, Nathan Beckmann, Mor Harchol-Balter, Gregory R. Ganger. 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI'20), Virtual Event, Nov. 4–6, 2020.
Abstract / PDF [606K] / Slides / Talk Video
- A Large Scale Analysis of Hundreds of In-memory Cache Clusters at Twitter. Juncheng Yang, Yao Yue, K. V. Rashmi. 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI'20), Virtual Event, Nov. 4–6, 2020.
Abstract / PDF [1.6M] / Slides / Talk Video
- Towards Lightweight and Robust Machine Learning for CDN Caching. Daniel S. Berger. HotNets-XVII, November 15–16, 2018, Redmond, WA, USA.
Abstract / PDF [610K]
- RobinHood: Tail Latency Aware Caching—Dynamic Reallocation from Cache-Rich to Cache-Poor. Daniel S. Berger, Benjamin Berg, Timothy Zhu, Siddhartha Sen, Mor Harchol-Balter. 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’18). October 8–10, 2018 • Carlsbad, CA, USA.
Abstract / PDF [2.9M]
- Practical Bounds on Offline Caching with Variable Object Sizes. Daniel Berger, Nathan Beckmann, Mor Harchol-Balter. Proc. ACM Meas. Anal. Comput. Syst., Vol. 2, No. 2, Article 32. June 2018. POMACS 2018.
Abstract / PDF [1.2M]
- LHD: Improving Cache Hit Rate by Maximizing Hit Density. Nathan Beckmann, Haoxian Chen, Asaf Cidon. 15th USENIX Symposium on Networked Systems Design and Implementation ({NSDI} 18), April 9-11, 2018, Renton, WA..
Abstract / PDF [1.1M]
- AdaptSize: Orchestrating the Hot Object Memory Cache in a Content Delivery Network. Daniel S. Berger, Ramesh K. Sitaraman, Mor Harchol-Balter. 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI '17). March 27–29, 2017, Boston, MA.
Abstract / PDF [560K]
Acknowledgements
We thank the members and companies of the PDL Consortium: Bloomberg LP, Everpure, Google, Jane Street, LayerZero Labs, Meta, Microsoft Research, Oracle Corporation, Salesforce, Uber, and Western Digital for their interest, insights, feedback, and support.