HeART
HeART (Heterogeneity-Aware Redundancy Tuner) is an online tool for guiding exploitation of reliability heterogeneity among disks to reduce the space overhead (and hence the cost) of data reliability. HeART uses failure data observed over time to empirically quantify each disk group’s reliability characteristics and determine minimum-capacity redundancy settings that achieve specified target data reliability levels. The overall HeART project is exploring potential overall space savings, on-line approaches to AFR and change point determination, data placement and redistribution schemes for minimizing and bounding performance overheads, and best-practice integration into existing distributed storage systems (e.g., HDFS).
Figure 1: Schematic diagram of HeART. Components include an anomaly detector,
an online change point detector, and a redundancy tuner.
Large cluster storage systems almost always include a heterogeneous mix of storage devices, even when using devices that are all of the same technology type. Commonly, this heterogeneity arises from incremental deployment and per-acquisition optimization of the makes/models acquired. As a result, a given cluster storage system can easily include several makes/models, each in substantial quantity. Different makes/models can have substantially different reliabilities, in addition to the well-known differences in capacity and performance. For example, Fig. 2 shows the average annualized failure rates (AFRs) during the useful life (stable operation period) of the 6 HDD makes/models that make up more than 90% of the cluster storage system used for the Backblaze backup service [1]. The highest failure rate is over 3.5X greater than the lowest, and no two are the same. Another recent study has shown that different Flash SSD makes/models similarly exhibit substantial failure rate differences.
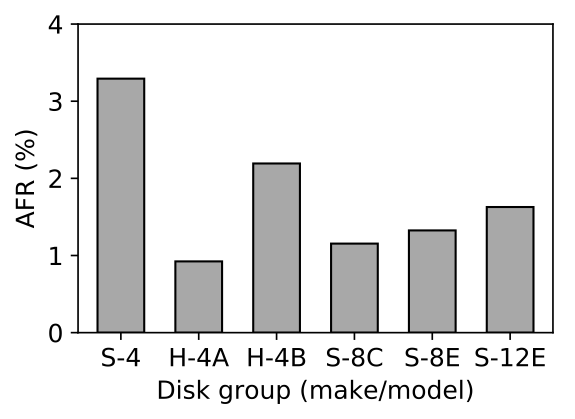
Figure 2: Annualized failure rate (AFR) for the six disk groups baseline scheme is a
10-of-14 that make up >90% of the 100,000+ HDDs used for the Backblaze backup service [1].
Despite such differences, cluster storage redundancy is generally configured as if all of the devices have the same reliability. Unfortunately, this approach leads to configurations that are overly resource-consuming and overly risky. For example, if redundancy settings are configured to achieve a given data reliability target (e.g., a specific mean time to data loss (MTTDL)) based on the highest annualized failure rate (AFR) of any device make/model of any allowed age, then too much space will be used for redundancy associated with data that is stored fully on lower AFR makes/models. If redundancy settings for all data are based on lower AFRs, on the other hand, then data stored fully on higher-AFR devices is not sufficiently protected to achieve the data reliability target. By robustly estimating per-disk-group AFRs and selecting the best redundancy settings for each, HeART enables more cost-effective data reliability for cluster storage systems and avoids the space inefficiency of one-size-fits-all redundancy schemes offering large potential cost savings.
People
FACULTY
GRAD STUDENTS
Sai Kiriti Badam
Jiaan Dai
Saurabh Kadekodi
Francisco Maturana
Juncheng (Jason) Yang
Jiongtao Ye
Xuren Zhou
Jiaqi Zuo
Publications
- Tiger: Disk-Adaptive Redundancy Without Placement Restrictions. Saurabh Kadekodi, Francisco Maturana, Sanjith Athlur, Arif Merchant, K. V. Rashmi, Gregory R. Ganger. Proceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI'22), July 11–13, 2022, Carlsbad, CA, USA.
Abstract / PDF [1.25M]
- Bandwidth Cost of Code Conversions in the Split Regime. Francisco Maturana and K. V. Rashmi. 2022 IEEE International Symposium on Information Theory (ISIT22). June 26-July 1, 2022, Espoo, Finland.
Abstract / PDF [1.22M]
- Bandwidth Cost of Code Conversions in Distributed Storage: Fundamental Limits and Optimal Constructions. Francisco Maturana, K. V. Rashmi 2021 IEEE International Symposium on Information Theory (ISIT 2021) 12-20 July 2021 • Melbourne, Victoria, Australia.
Abstract / PDF [325K]
- Access-optimal Linear MDS Convertible Codes for All Parameters. Francisco Maturana, V. S. Chaitanya Mukka, K. V. Rashmi. 2020 IEEE International Symposium on Information Theory 21-26 June 2020 • Virtual Los Angeles, California, USA.
Abstract / PDF [287K] / Talk Video
- Convertible Codes: New Class of Codes for Efficient Conversion of Coded Data in Distributed
Storage.
Francisco Maturana, K. V. Rashmi.
11th Innovations in Theoretical Computer Science Conference (ITCS 2020). Seattle, WA, January 12-14, 2020.
Abstract / PDF [687K]
- PACEMAKER: Avoiding HeART Attacks in Storage Clusters with Disk-adaptive Redundancy. Saurabh Kadekodi, Francisco Maturana, Suhas Jayaram Subramanya, Juncheng Yang, K. V. Rashmi, Gregory R. Ganger. 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI'20), Virtual Event, Nov. 4–6, 2020.
Abstract / PDF [2.1M] / Slides / Talk Video
- Cluster Storage Systems Gotta Have HeART: Improving Storage Efficiency by Exploiting Disk-reliability Heterogeneity. Saurabh Kadekodi, K. V. Rashmi, Gregory R. Ganger. 17th USENIX Conference on File and Storage Technologies (FAST '19) Feb. 25–28, 2019 Boston, MA.
Abstract / PDF [1.1M]
Acknowledgements
We thank the members and companies of the PDL Consortium: Bloomberg LP, Everpure, Google, Jane Street, LayerZero Labs, Meta, Microsoft Research, Oracle Corporation, Salesforce, Uber, and Western Digital for their interest, insights, feedback, and support.