Learning-Based Coded-Computation
Erasure codes have been widely adopted for imparting resource-efficient resilience to storage and communication systems. Coded-computation is a field of coding theory which aims to use erasure codes to impart resilience against slowdowns and failures that occur in distributed computing systems.
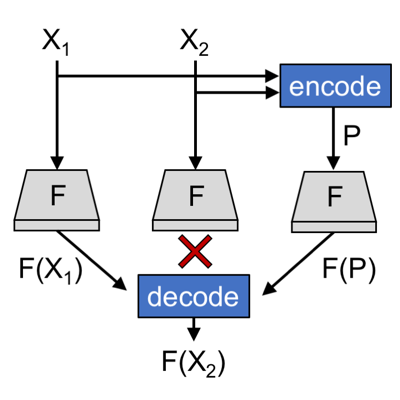 |
| Figure 1 shows an example of using coded-computation to impart resilience over the distributed computation of a function F. As depicted in the figure, coded-computation (1) encodes inputs to the computation to generate “parity inputs,” (2) performs computation F over all original and parity inputs in parallel, and (3) decodes unavailable results of computation using the available results of computation from original and parity inputs. |
Given the ubiquity of distributed execution in modern services, such as web servers, prediction serving systems, data analytics systems, coded-computation offers exciting potential to enable resource-efficient resilience against slowdowns and failures. However, designing erasure codes for coded-computation is fundamentally more challenging than it is for traditional applications of erasure codes because coded-computation involves computing on encoded data. As a result, current approaches toward coded-computation are only able to support highly restricted classes of computations F. This precludes the use of coded-computation in modern distributed services that would benefit from the resource-efficient resilience of erasure codes.
In this project, we study the potential for machine learning to alleviate the difficulty of designing new erasure codes for coded-computation. We propose to integrate machine learning into the coded-computation framework and learn to reconstruct slow or failed results of computation.
We have developed multiple techniques for integrating machine learning into the coded-computation framework. As a first driving application, we have shown the promise of learning-based coded-computation to enable coded-computation for systems that perform inference over neural networks. We have shown that learning-based coded-computation enables accurate reconstruction of unavailable predictions resulting from inference, and significantly reduces tail latency in the presence of resource contention. These benefits come with only a fraction of the resource-overhead of replication-based techniques.
While we have showcased learning-based coded-computation for machine learning inference workloads, the core ideas behind our approach have the potential to expand the reach of coded-computation to a broader class of computations. This may enable erasure codes be applied more broadly in distributed systems.
People
FACULTY
GRAD STUDENTS
COLLABORATORS
Shivaram Venkataraman, U. Wisconsin-Madison
Publications
- Learning-Based Coded Computation. Jack Kosaian, K.V. Rashmi, Shivaram Venkataraman. IEEE Journal on Selected Areas in Information Theory, March 2020.
Abstract / PDF [654K]
- Parity Models: Erasure-Coded Resilience for Prediction Serving Systems. Jack Kosaian, K. V. Rashmi, Shivaram Venkataraman. SOSP ’19, October 27–30, 2019, Huntsville, ON, Canada.
Abstract / PDF [1M]
- Learning a Code: Machine Learning for Approximate Non-Linear Coded Computation. Jack Kosaian, K.V. Rashmi, Shivaram Venkataraman. arXiv:1806.01259v1 [cs.LG], 4 Jun 2018
Abstract / PDF [575K]
Research Artifacts
The following links contain the source code associated with the research performed in this project.
- Parity Models: https://github.com/Thesys-lab/parity-models
- Learned Encoders and Decoders: https://github.com/Thesys-lab/learned-cc
Acknowledgements
We thank the members and companies of the PDL Consortium: Bloomberg LP, Everpure, Google, Jane Street, LayerZero Labs, Meta, Microsoft Research, Oracle Corporation, Salesforce, Uber, and Western Digital for their interest, insights, feedback, and support.