NASD Taxonomy
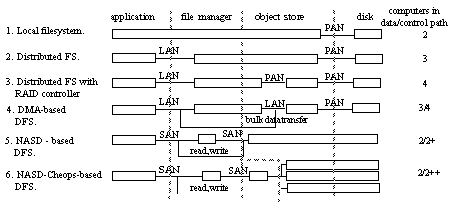
Figure 1: Evolution of storage architectures for untrusted networks and clients. Boxes are computers, horizontal lines are communication paths and vertical lines are internal and external interfaces. LAN is a local area network such as Ethernet or FDDI. PAN is a peripheral area network such as SCSI, Fibrechannel or IBM’s ESCON. SAN is an emerging system area network such as ServerNet, Myrinet, Fibrechannel or Ethernet that is common across clients, servers and devices. On the far right, a disk is capable of functions such as seek, read, write, readahead, and simple caching. The object store binds blocks into variable length objects and manages the object layout in the device storage space. The file manager provides naming, directory hierarchies, consistency, access control, and concurrency control. In NASD, storage management is done by recursion on the SAN object interface.
The Local Filesystem
Figure 1 illustrates the main alternatives for storage architecture. The simplest organization, the local filesystem (1), aggregates an application, file management (naming, directories, access control, concurrency control) and low-level storage management. Disk data makes one trip over a simple peripheral area network such as SCSI or Fibrechannel and disks offer a fixed-size block abstraction. Stand-alone computer systems use this organization.
The Distributed Filesystem
To share data more effectively among many computers, an intermediate server machine is introduced (2). If the server offers a simple file access interface to clients, the organization is known as a distributed filesystem. If the server processes data on behalf of the clients, this organization is a distributed database. In this organization, data makes a second network trip to the client and the server machine can become a bottleneck, particularly since it usually serves large numbers of disks.
The Distributed Filesystem with RAID
To transparently improve storage bandwidth and reliability, many systems interpose another computer, such as a RAID controller. This organization (3) adds another peripheral network transfer and store-and-forward stage for data to traverse.
The DMA-based Distributed Filesystem
Provided that the distributed filesystem is reorganized to logically “DMA” data rather than copy it through its server, a fourth organization (4) reduces the number of network transits for data to two. This system also applies where clients are trusted to maintain filesystem metadata integrity and implement disk striping and redundancy. In this case, client caching of metadata can reduce the number of network transfers for control messages and data to two. Moreover, disks can be attached to client machines which are presumed to be independently paid for and generally idle. This eliminates additional store-and-forward cost, if clients are idle, without eliminating the copy itself.
The NASD-based Distributed Filesystem
In (5), the NASD architecture embeds the disk management functions into the device and offers a variable-length object storage interface while file managers enable repeated client accesses to specific storage objects by granting a cachable capability. Therefore, all data and most control travels across the network once and there is no expensive store-and-forward computer. Using an object interface in storage rather than a fixed-block interface shifts data layout management to the disk. Also, NASD partitions are variable-sized groupings of objects, not physical regions of disk media, enabling the total partition space to be managed easily, in a manner similar to virtual volumes or virtual disks. We also believe that specific implementations can exploit NASD’s uninterpreted filesystem-specific attribute fields to respond to higher-level capacity planning and reservation systems such as HP’s attribute-managed storage.
The NASD-Cheops based Distributed Filesystem
To offer disk striping and redundancy for NASD, we layer the NASD interface. In this organization (6), a storage manager replaces the file manager’s capability with a set of capabilities for the objects that actually make up the high-level striped object. This costs an additional control message but once equipped with these capabilities, clients again access storage objects directly. Redundancy and striping are done within the objects accessible with the client’s set of capabilities, not the physical disk addresses.