Attribute-Based Naming
Inferring Attributes From Context
As storage capacity continues to increase, users find it increasingly
difficult to manage their files using traditional directory hierarchies.
Attribute-based naming enables powerful search and organization tools
for ever-increasing user data sets. However, such tools are only useful
in combination with accurate attribute assignment. Existing systems
rely on user input and content analysis, but they have enjoyed minimal
success. We propose several new approaches to automatically assigning
attributes to files through context analysis, a technique that has been
successful in the Google web search engine. With extensions like application
hints (e.g., web links for downloaded files) and inter-file relationships,
it should be possible to infer useful attributes for many files, making
attribute-based search tools more effective.
Existing Organizational Tools
As storage capacity increases, the amount of data belonging to an individual user increases accordingly. Soon, storage capacity will reach a point where there will be no reason for a user to ever delete old content — in fact, the time required to do so would be wasted. The challenge has shifted from deciding what to keep to finding particular information when it is desired. To meet this challenge, we need to improve our approach to personal data organization.
Today, most systems provide a tree-like directory hierarchy to organize files. Although this is easy for most users to understand, it does not provide the flexibility required to scale to large numbers of files. In particular, the strict hierarchy provides only a single categorization with no cross-referenced information.
Alternatives to the standard directory hierarchy systems generally assign attributes to files, providing the ability to cluster and search for files by their attributes. An attribute can be any metadata that describes the file, although most systems use keywords or <category, value> pairs. The key challenge is assigning useful, meaningful attributes to files.
Unfortunately, the two most prevalent methods of attribute assignment,
user input and content analysis, have been largely unsuccessful. Although
users often have a good understanding of the files they create, it can
be time-consuming and unpleasant to distill that information into the
right set of keywords. As a result, users are understandably reluctant
to do so. On the other hand, content analysis takes none of the user’s
time, and can be performed entirely in the background to eliminate any
potential performance penalty. However, the complexity of language parsing,
combined with the large number of proprietary file formats and non-textual
data types, restricts the effectiveness of content analysis.
Context-based Attributes
Early web search-engines, (e.g. Lycos), relied upon user input (user submitted web pages) and content analysis (word counts, word proximity, etc.). Although valuable, the success of these systems has been eclipsed by the success of Google.
To provide better search results, Google utilizes two forms of context analysis. First, it uses the text associated with a link to determine attributes for the linked site. This text gives the context of both the creator of the linking site and the user who clicks on the link at that site. The more times that a particular word links to a site, the higher that word is ranked for that site. Second, Google uses the actions of a user after a search to decide what the user wanted from that search. For example, if a user clicks on the first four links of a given search, and then does not return, it is likely that the fourth link was the best match, providing the user’s context for those search terms.
Unfortunately, Google’s approach to indexing does not translate
directly into the realm of file systems. Much of the information that
Google relies on does not exist within a file system. Also, Google’s
query feedback mechanism relies on two properties: users are normally
looking for the most popular sites when they perform a query, and they
have a large user base that will repeat the same query many times. Conversely,
in file systems, users usually search for files that have not been accessed
in a long time, because they usually remember where recently accessed
files reside, and there is generally only a single user for each set
of files, making it unlikely that frequent queries will be generated
for any given file.
Context-based Attributes in File Systems
We are investigating four approaches to automatically gathering context information for use in file systems. The first two focus on gathering attributes when a file is created or accessed. The second two focus on propagating attributes among related files to increase the coverage of attribute assignment. Together, these techniques should categorize a much broader set of files than creation-based attribute assignment alone.
Application assistance: Although computers provide a vast array of functionality, most people use their computer for a limited set of tasks using a small set of applications that, in turn, access and create most of the user’s files. Modifying these applications to provide hints about the user’s context could provide invaluable attribute information.
Existing user input: Although most users are not willing to input additional information, they are willing to choose a directory and name for their files. Each of the sub-directories along the path and the file name itself probably contain context information that can be used to assign attributes. For example, if the user stores a file in “/home/papers/FS/Attribute-based/Semantic91.ps,” then it is likely that they believe the file is a “paper” having to do with “FS,” “attribute-based,” and “semantic.”
User access patterns: As users access their files, the pattern of their accesses provides a set of temporal relationships between files. A possible use of this information is to help propagate information between related files. For example, accessing “SemanticFS.ps” and “Gopal.ps” followed by updating “related.tex” may indicate a relationship between the three files. Subsequently, accessing “related.tex” and creating “FindingFiles.ps” may indicate a transitive relationship.
Inter-file content analysis: Content analysis will continue
to be an important part of automatically assigning attributes. In addition
to existing per-file analysis techniques, our focus on creating context-based
connections between files suggests another source of attributes: content-based
relationships. For example, some current file systems use hashing to
eliminate duplicate blocks within a file system, or even locate similarities
on non-block aligned boundaries. Such content overlap could also be
used to identify related files, by treating files with large matching
data sets as related. Similarly, users (or the system) will often keep
several slightly different versions of a file. Although these files
generally contain differences, often the inherent information contained
within does not change (e.g., a user may keep three instances of their
resume, each focused for a different type of job application). This
gives the system two opportunities for content analysis. First, content
comparison can identify related files. Second, by performing content
analysis solely on the differences between versions, it may be possible
to determine version-specific attributes, making it easier for users
to locate individual version instances.
Prototype Evaluation System
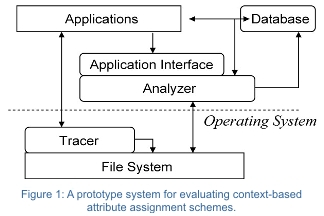 |
| A prototype system for evaluation context-based attribute assignment schemes. |
This figure shows an overview of a prototype system for evaluating context-based
attribute assignment schemes. The system is composed of four main parts:
the tracer, the application interface, the analyzer, and the database. The tracer keeps a trace of all file system activity in
the system. Any file system calls made by applications are tracked and
stored in a file for later offline analysis. This allows a single system
to employ a variety of different analysis techniques. The application
interface allows applications to pass context information into the system,
such as email header information or link information from a web browser.
This information is used by the analyzer to generate attributes for
files. The analyzer combines application information, and offline trace
analysis to generate attributes for files. All updated attribute information
is passed to the database, which provides the search interface to the
application. It allows applications to locate files using the file attributes
assigned by the analyzer. Feedback from the search results is pushed
to the analyzer for further attribute refinement.
This design could include multiple databases. In order to compare the
results of different trace analysis algorithms, the analyzer could maintain
a database for each, and users could compare the results of the different
approaches. For more information on this project see Soules [1].
Reference
- Craig A.N. Soules, Greg Ganger. Why Can’t I Find My Files? New methods for automating attribute assignment. Proceedings of the Ninth HotOS Workshop, USENIX Association, May 2003.