pWalrus: Layering S3 on Parallel File Systems
Amazon S3-style storage is an attractive option for clouds that provides data access over HTTP/HTTPS. At the same time, parallel file systems are an essential component in privately owned clusters that enable highly scalable data-intensive computing. In this work, we take advantage of both of those storage options, and propose pWalrus, a storage service layer that integrates parallel file systems effectively into cloud storage. Essentially, it exposes the mapping between S3 objects and backing files stored in an underlying parallel file system, and allows users to selectively use the S3 interface and direct access to the files.
pWalrus Architecture
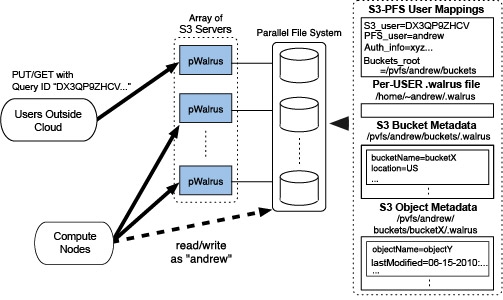
pWalrus is structured as an array of S3 service serves that are backed by one shared parallel file system. As user data and management data are stored in the parallel file system, all S3 servers share the same view of S3 storage. Thus, users can connect to any of the servers to access their data through the S3 interface. This creates the opportunity for load balancing and exploiting the scalability of the underlying parallel file system. In addition, pWalrus allows for direct access to data in the file system by exposing the mapping between S3 objects and the corresponding files backing them. By selectively using either interface to data, users can benefit from the strengths, and avoid the restrictions, of S3 storage and parallel file systems, which complement each other as summarized below.
| Strengths | Restrictions | |
|---|---|---|
| S3 | - Facilitated access through a uniform interface - Universal accessibility regardless of user environments |
- PUT/GET access to objects in their entirety |
| Parallel File Systems | - Scalable performance - POSIX interface with partial reads and writes |
- Require administrative work to allow access |
pWalrus with HDFS
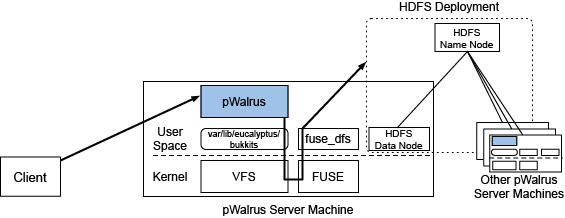
pWalrus accesses its backing parallel file system through the POSIX interface, as a locally mounted file system. As a result, pWalrus can work with HDFS by accessing it through FUSE, as shown above. In this deployment model, pWalrus sever machines act also as Data Nodes and mount HDFS to access it.
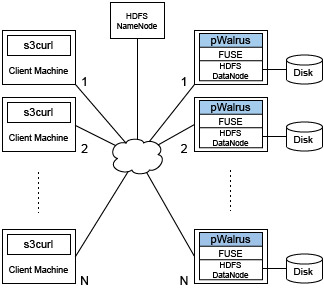
Preliminary measurements were performed with the set-up shown above. There are N (1, 2, ..., 16) pWalrus servers and N clients running on distinct physical machines. The clients make concurrent REST S3 requests to the pWalrus service, each downloading a 2 GB object. Both the number of servers and that of clients are scaled, and the number of client request per server is kept 1. The server and client machines are equipped with two quad-core 2.83 or 3.0 GHz CPUs and 16 GB of memory (except two client machines having 32 GB of memory), and are connected through a 10 Gbps network. Each server machine uses a SATA 7200 RPM hard disk with a 1 TB capacity (xfs file system) as the physical storage for its HDFS Data Node. All the machines run Linux kernel version 2.6.32, and the version of Hadoop used is 0.20.2.
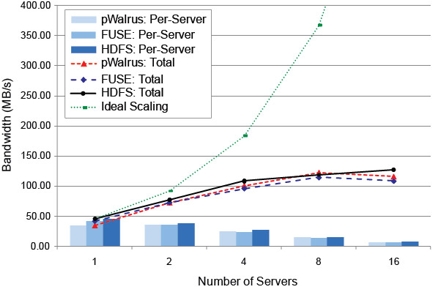
The graph compares per-server and aggregate download bandwidth of the pWalrus service to two baselines. Data labeled "FUSE" shows the corresponding bandwidth when the clients mount HDFS directly and then copy objects from it to a local file system. Data labeled "HDFS" is when the clients use "bin/hadoop dfs -get" command to copy the objects. pWalrus exposes the performance of the underlying file system effectively through the S3 interface. Note that the limited scalability of the shown results would be due to our naive configuration of HDFS deployment, which was not tuned to fully exploit its capability.
People
FACULTY
Garth Gibson
GRAD STUDENTS
Yoshihisa Abe
Publications
- pWalrus: Towards Better Integration of Parallel File Systems into Cloud Storage. Yoshihisa Abe, Garth Gibson. Workshop on Interfaces and Abstractions for Scientific Data Storage (IASDS10), co-located with IEEE Int. Conference on Cluster Computing 2010 (Cluster10), Heraklion, Greece, September 2010.
Abstract / PDF [321K]
Acknowledgements
We would like to thank Rich Wolski and Neil Soman of Eucalyptus for their explanations and advice, and our anonymous reviewers for their useful comments. The work in this paper is based on research supported in part by the Betty and Gordon Moore Foundation, by the Department of Energy, under award number DE-FC02-06ER25767, by the Los Alamos National Laboratory, under contract number 54515-001-07, and by Google and Yahoo! research awards.
We thank the members and companies of the PDL Consortium: Bloomberg LP, Datadog, Google, Intel Corporation, Jane Street, LayerZero Labs, Meta, Microsoft Research, Oracle Corporation, Oracle Cloud Infrastructure, Pure Storage, Salesforce, Samsung Semiconductor Inc., Uber, and Western Digital for their interest, insights, feedback, and support.