Database I/O
Database systems are among the most important application domains for
storage systems. Currently, we are approaching database research on
several fronts, with a common goal of identifying innovative ways to
improve system performance by better matching database systems to the
underlying hardware.
Staged Database Systems
Traditional database system architectures face a rapidly evolving operating
environment, where millions of users store and access terabytes of data.
In order to cope with increasing demands for performance high-end DBMS
employ parallel processing techniques coupled with a plethora of sophisticated
features. However, the widely adopted, work-centric, thread-parallel
execution model entails several shortcomings that limit server performance
when executing workloads with changing requirements. Moreover, the monolithic
approach in DBMS software has led to complex and difficult to extend
designs. This project introduces a staged design for high-performance,
evolvable DBMS that is easy to tune and maintain. We propose to break
the database system into modules and to encapsulate them into self-contained
stages connected to each other through queues. The staged, data-centric
design remedies the weaknesses of modern DBMS by providing solutions
at both a hardware and a software engineering level.
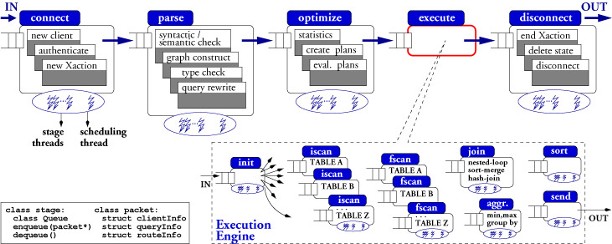
|
| The Staged Database System design: Each stage has its own queue and thread support. New queries queue up in the first stage, they are encapsulated into a "packet", and pass through the five stages shown on the top of the figure. A packet carries the query’s "backpack:" its state and private data. Inside the execution engine a query can issue multiple packets to increase parallelism. |
Architecture-Conscious Database Systems: The PAX Storage Model
When optimizing cache utilization, data placement is extremely important.
In commercial DBMSs, data misses in the cache hierarchy are a key memory
bottleneck. The traditional data placement scheme used in DBMSs, the
N-ary Storage Model (NSM), stores records contiguously starting from
the beginning of each disk page, and uses an offset (slot) table at
the end of the page to locate the beginning of each record and offers
high intra-record locality. Recent research, however, indicates that
cache utilization and performance is becoming increasingly important
on modern platforms. This project first demonstrates that in-page data
placement is the key to high cache performance and that NSM exhibits
low cache utilization on modern platforms. Therefore, we propose a new
data organization model called PAX (Partition Attributes Across), that
significantly improves cache performance by grouping together all values
of each attribute within each page. Because PAX only affects layout
inside the pages, it incurs no storage penalty and does not affect I/O
behavior. When compared to NSM, our experimental results indicate that
(a) PAX exhibits superior cache and memory bandwidth utilization, saving
at least 75% of NSM's stall time due to data cache accesses, (b) range
selection queries and updates on memory-resident relations execute 17-25%
faster, and (c) TPC-H queries involving I/O execute 11-48% faster. We
have also found that PAX performs well across different memory system
designs.
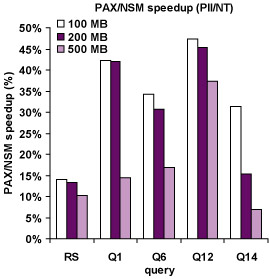
|
| PAX/NSM speedup for DSS queries: Shows PAX/NSM speedups when running range selections and four TPC-H queries against a 100, 200, and 500-MB TPC-H database on top of the Shore storage manager. Decision-support systems are especially processor- and memory-bound, and PAX outperforms NSM for all these experiments. The speedups obtained are not constant across the experiments due to a combination of differing amounts of I/O and interactions between the hardware and the algorithms being used. |
Improving Database Performance through Prefetching
We are exploring the latency hiding approaches, cache prefetching and I/O prefetching, to improve database performance. We have used cache prefetching to improve main memory B+tree performance (SIGMOD'01), studied fractal prefetching B+trees to optimize both disk and cache performance with a single index structure (SIGMOD'02), and improved hash join performance with prefetching (submitted). We are now focusing on prediction schemes using history information to improve general join algorithms.
Fractal Prefetching B+trees: Optimizing Both Cache and Disk Performance
Fractal Prefetching B+-Trees (fpB+-Trees) are a type of B+-Tree that optimize both cache and I/O performance by embedding "cache-optimized" trees within "disk-optimized" trees. This improves CPU cache performance in traditional B+-Trees for indexing disk resident data and I/O performance in B+-Trees optimized for cache. At a coarse granularity an fpB+-Tree contains disk-optimized nodes that are roughly the size of a disk page; at a fine granularity, it contains cache-optimized nodes that are roughly the size of a cache line. The fpB+-Tree is referred to as "fractal" because of its self-similar "tree within a tree" structure.
Recently, researchers have proposed new types of B+-Trees optimized
for CPU cache performance in main memory environments, where the tree
node sizes are one or a few cache lines. Unfortunately, due primarily
to this large discrepancy in optimal node sizes, existing disk-optimized
B+-Trees suffer from poor cache performance while cache-optimized B+-Trees
exhibit poor disk performance. We propose fractal prefetching B+-Trees
(fpB+-Trees), which embed "cache-optimized" trees within "disk-optimized"
trees, in order to optimize both cache and I/O performance. We design
and evaluate two approaches to breaking disk pages into cache-optimized
nodes: disk-first and cache-first. These approaches are somewhat biased
in favor of maximizing disk and cache performance, respectively, as
demonstrated by our results. Both implementations of fpB+-Trees achieve
dramatically better cache performance than disk-optimized B+-Trees:
a factor of 1.1-1.8 improvement for search, up to a factor of 4.2 improvement
for range scans, and up to a 20-fold improvement for updates, all without
significant degradation of I/O performance. In addition, fpB+-Trees
accelerate I/O performance for range scans by using jump-pointer arrays
to prefetch leaf pages, thereby achieving a speed-up of 2.5-5 on IBM's
DB2 Universal Database.
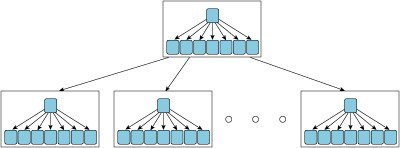
|
Self-similar "tree within a tree" structure. |
Active Disks
Today's commodity disk drives, the basic unit of storage for computer systems large and small, are actually small computers, with a processor, memory, and 'network' connection, along with the spinning magnetic material that permanently stores the data. As more and more of the information in the world becomes digitally available, and more and more of our daily activities are recorded and stored, people are increasingly finding value in analyzing, rather than simply storing and forgetting, these large masses of data. Sadly, advances in I/O performance have lagged the development of commodity processor and memory technology, putting pressure on systems to deliver data fast enough for these types of data-intensive analysis. Active Disks is a system that takes advantage of the processing power on individual disk drives to run application-level code. Moving portions of an application's processing directly to the disk drives can dramatically reduce data traffic and take advantage of the parallelism already present in large storage systems, providing a new point of leverage to overcome the I/O bottleneck.
For more information on Active Disks, please see the Active Disks project page.
People
FACULTY
Anastassia Ailamaki
Todd Mowry
STUDENTS
Stavros Harizopoulos
Minglong Shao
Stratos Papadomanolakis
Shimin Chen
Publications
- Scheduling Threads for Constructive Cache Sharing on CMPs. Shimin Chen, Phillip B. Gibbons, Michael Kozuch, Vasileios Liaskovitis, Anastassia Ailamaki, Guy E. Blelloch, Babak Falsafi, Limor Fix, Nikos Hardavellas, Todd C. Mowry, Chris Wilkerson. SPAA'07, June 9-11, 2007, San Diego, California, USA.
Abstract / PDF [293K]
- MultiMap: Preserving Disk Locality for Multidimensional Datasets. Minglong Shao, Steven W. Schlosser, Stratos Papadomanolakis, Jiri Schindler, Anastassia Ailamaki, Gregory R. Ganger. IEEE 23rd International Conference on Data Engineering (ICDE 2007) Istanbul, Turkey, April 2007. Supercedes Carnegie Mellon University Parallel Data Lab Technical Report CMU-PDL-05-102. March 2005.
Abstract / PDF [203K]
- Database Servers on Chip Multiprocessors: Limitations and Opportunities. Nikos Hardavellas, Ippokratis Pandis, Ryan Johnson, Naju G. Mancheril, Anastassia Ailamaki and Babak Falsafi. 3rd Biennial Conference on Innovative Data Systems Research (CIDR), January 7-10, 2007, Asilomar, California, USA.
Abstract / PDF [111K]
- Brief Announcement: Parallel Depth First vs. Work Stealing Schedulers on CMP Architectures. Vasileios Liaskovitis, Shimin Chen, Phillip B. Gibbons, Anastassia Ailamaki, Guy E. Blelloch, Babak Falsafi, Limor Fix, Nikos Hardavellas, Michael Kozuch, Todd C. Mowry, Chris Wilkerson. SPAA’06, July 30-August 2, 2006, Cambridge, Massachusetts, USA.
Abstract / PDF [52K]
- On Multidimensional Data and Modern Disks. Steven
W. Schlosser, Jiri Schindler, Stratos Papadomanolakis , Minglong Shao
Anastassia Ailamaki, Christos Faloutsos, Gregory R. Ganger. Proceedings
of the 4th USENIX Conference on File and Storage Technology (FAST
'05). San Francisco, CA. December 13-16, 2005.
Abstract / PDF [220K]
- QPipe: A Simultaneously Pipelined Relational Query Engine.
Stavros Harizopoulos, Vladislav Shkapenyuk, Anastassia Ailamaki. SIGMOD
2005, June 14-16, 2005, Baltimore, Maryland, USA.
Abstract / PDF [288K]
- MultiMap: Preserving disk locality for multidimensional datasets.
Minglong Shao, Steven W. Schlosser, Stratos Papadomanolakis, Jiri
Schindler, Anastassia Ailamaki, Christos Faloutsos, and Gregory R.
Ganger. Carnegie Mellon University Parallel Data Lab Technical Report
CMU-PDL-05-102. March 2005.
Abstract / PDF [318K]
- STEPS Towards Cache-Resident Transaction Processing. Stavros
Harizopoulos, Anastassia Ailamaki. Proceedings of the 30th VLDB Conference,
Toronto, Canada, 29 August - 3 September 2004.
Abstract / PDF [332K]
- Clotho: Decoupling Page Layout from Storage Organization.
Minglong Shao, Jiri Schindler, Steven W. Schlosser, Anastassia Ailamaki,
Gregory R. Ganger. Proceedings of the 30th VLDB Conference. Toronto,
Canada, 29 August - 3 September 2004. Supercedes Carnegie Mellon University
Parallel Data Lab Technical Report CMU-PDL-04-102, March 2004.
Abstract / PDF [203K]
- AutoPart: Automating Schema Design for Large Scientific Databases
Using Data Partitioning. Stratos Papadomanolakis, Anastassia Ailamaki.
16th International Conference on Scientific and Statistical Database
Management (SSDBM). Santorini Island, Greece. June 21-23, 2004.
Abstract / Postscript [1M] / PDF [150K]
- Matching Application Access Patterns to Storage Device Characteristics. Jiri Schindler. Carnegie Mellon University Ph.D Dissertation. CMU-PDL-03-109,
May 2004.
Abstract / PDF [1.14M]
- Improving Hash Join Performance through Prefetching. Shimin
Chen, Anastassia Ailamaki, Philip B. Gibbons, Todd C. Mowry. Proceedings
of the 20th International Conference on Data Engineering (ICDE 2004).
Boston, MA. March 30 to April 2, 2004.
Abstract / Postscript [ 2.2M] / PDF [330K]
- Atropos: A Disk Array Volume Manager for Orchestrated Use of
Disks. Jiri Schindler, Steven W. Schlosser, Minglong Shao, Anastassia
Ailamaki, Gregory R. Ganger. Proceedings of the 3rd USENIX Conference
on File and Storage Technologies (FAST '04). San Francisco, CA. March
31, 2004. Supercedes Carnegie Mellon University Parallel Data Lab
Technical Report CMU-PDL-03-101, December, 2003.
Abstract / PDF [281K]
- Diamond: A Storage Architecture for Early Discard in Interactive
Search. Larry Huston, Rahul Sukthankar, Rajiv Wickremesinghe,
M. Satyanarayanan, Gregory R. Ganger, Erik Riedel, Anastassia Ailamaki.
Proceedings of the 3rd USENIX Conference on File and Storage Technologies
(FAST '04). San Francisco, CA. March 31, 2004.
Abstract / Postscript [2.2M] / PDF [266K]
- Lachesis: Robust Database Storage Management Based on Device-specific
Performance Characteristics. Jiri Schindler, Anastassia Ailamaki,
Gregory R. Ganger. VLDB 03, Berlin, Germany, Sept 9-12, 2003. Also
available as Carnegie Mellon University Technical Report CMU-CS-03-124,
April 2003.
Abstract / Postscript [510K] / PDF [152K]
- Improving Hash Join Performance through Prefetching. Shimin
Chen, Anastassia Ailamaki, Phillip B. Gibbons, Todd C. Mowry. In submission.
- A Case for Staged Database Systems. S. Harizopoulos and A.
Ailamaki. In proceedings of the First International Conference on
Innovative Data Systems Research (CIDR), Asilomar, CA, January 2003.
Abstract / Postscript [820K] / PDF [153K]
- Data Page Layouts for Relational Databases on Deep Memory Hierarchies.
A. Ailamaki, D.J. DeWitt, and M.D. Hill. The VLDB Journal 11(3), 2002.
Abstract / Postscript [977K] / PDF [177K]
- Fractal Prefetching B+trees: Optimizing Both Cache and Disk Performance. Shimin Chen, Phillip B. Gibbons, Todd C. Mowry, and Gary Valentin.
Proceedings of SIGMOD 2002, June 2002, Madison, Wisc. Also available
as CMU SCS Technical Report CMU-CS-02-115.
Abstract / Postscript [2.2M] / PDF [335K]
- Affinity Scheduling in Staged Server Architectures. Stavros
Harizopoulos and Anastassia Ailamaki. Carnegie Mellon University Technical
Report CMU-CS-02-113, March 2002.
Abstract / Postscript [982K] / PDF [186K]
- Improving Index Performance through Prefetching. Shimin
Chen, Phillip B. Gibbons, and Todd C. Mowry. In proceedings of SIGMOD
2001, Santa Barbara, CA, May 2001. Also available as a technical report
CMU-CS-00-177.
Abstract / Postscript [1.8M] / PDF [323K]
- Active Disks for Large-Scale Data Processing. Riedel, E.,
Faloutsos, C., Gibson, G.A. and Nagle, D.F. IEEE Computer, June 2001.
Abstract / PDF [722K]
- Data Mining on an OLTP System (Nearly) for Free. Riedel,
E., Faloutsos, C., Ganger, G.R. and Nagle, D.F. Proc. of the 2000
ACM SIGMOD International Conference on Management of Data, Dallas,
Texas, May 14-19, 2000. Also available as CMU SCS Technical Report
CMU-CS-99-151.
Abstract / Postscript [1.0M] / PDF [171K]
- Active Storage For Large-Scale Data Mining and Multimedia. Riedel, E., Gibson, G.A and Faloutsos, C. Proc. of the 24th International
Conference on Very large Databases (VLDB '98), New York, New York,
August 24-27, 1998.
Abstract / Postscript [3.5M] / PDF [231K]
Acknowledgements
We thank the members and companies of the PDL Consortium: Amazon, Google, Hitachi Ltd., Honda, Intel Corporation, IBM, Meta, Microsoft Research, Oracle Corporation, Pure Storage, Salesforce, Samsung Semiconductor Inc., Two Sigma, and Western Digital for their interest, insights, feedback, and support.