DeltaFS: Rethinking File Systems for the Exascale Era

Over the years, improvements in storage and network hardware, as well as systems software, have been instrumental in mitigating the effect of I/O bottlenecks in HPC applications. Still, many scientific applications that read and write data in small chunks are limited by the ability of both the hardware and the software to handle such workloads efficiently. This problem will be exacerbated with exascale computers, which will allow scientific applications to run simulations at significantly larger scales. Even worse, scientific data is typically persisted out of order, creating the need to budget time and resources for a costly, massive sorting operation.
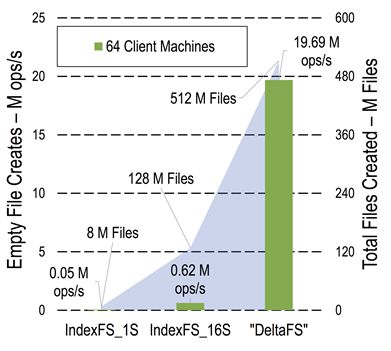
DeltaFS is a new distributed file system service that addresses these issues. To deal with the immense metadata load resulting from handling a large number of files, DeltaFS remains transient and software-defined. The transient property allows each application using DeltaFS to individually start, stop, and control the amount of computing resources dedicated to the file system by bootstrapping its own DeltaFS service across as many nodes as it needs, effectively controlling metadata performance. When combined with DeltaFS’s software-defined nature, this allows file system design and provisioning decisions to be decoupled from the overall design of HPC platforms. Our experiments (Figure 1) show that these properties allow DeltaFS to process two orders of magnitude more file creation operations compared to prior approaches.
|
Figure 1: File creation throughput with DeltaFS and prior work (IndexFS) |
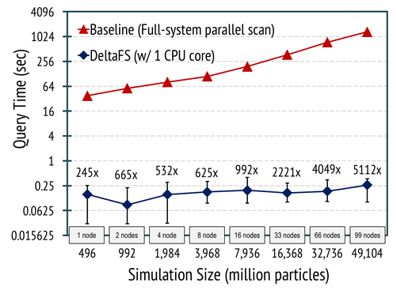
Another important goal of DeltaFS is to guarantee both fast writing and reading in the case of workloads consisting of small I/O transfers. A popular scientific application that would benefit from this is Vector-Particle-in-Cell (VPIC). VPIC simulates the movement of individual particles through their interactions, and can output particle data for each simulated time step out of order. Scientists, however, are mostly interested in accessing all data for a given particle, e.g. to study its trajectory. To improve the performance of such applications, DeltaFS uses Indexed Massive Directories (IMDs). WIthin this special directory type, out-of-order writes to a massive number of files get indexed in-situ as data is written to storage. This indexing enables quick data accesses, without the need for post-processing the data. Our VPIC experiments show a 5,000x speedup when particle trajectories are accessed through DeltaFS when 99 compute nodes are used on the LANL Trinity supercomputer. We expect further improvement as simulation size (i.e., output size) increases.
|
Figure 2: Performance of particle trajectory queries under DeltaFS |
People
FACULTY
George Amvrosiadis
Chuck Cranor
Greg Ganger
GRAD STUDENTS
Qing Zheng
Saurabh Kadekodi
ALUMNI
Kai Ren
PARTNERS
Los Alamos National Laboratory: Gary Grider, Brad Settlemyer, Fan Guo
Argonne National Laboratory: Robert B. Ross, Philip Carns, Matthieu Dorier, Robert Latham,
Shane Snyder
The HDF Group: Jerome Soumagne
In the News
- LANL Open Sources DeltaFS software for Wrangling Trillions of Files. Inside HPC, March 15, 2019.
- Handling Trillions of Supercomputer Files Just Got Simpler. Los Alamos National Laboratory News, March 14, 2019.
- CMU's DeltaFS Team Aims To Create Smarter Ways To Organize, Store Supercomputer Data. Carnegie Mellon University News, January 2019.
- This Bomb-simulating US Supercomputer Broke a World Record. Wired, July 23, 2018.
Publications
- DeltaFS: A Scalable No-Ground-Truth Filesystem For Massively-Parallel Computing. Qing Zheng, Chuck Cranor, Greg Ganger, Garth Gibson, George Amvrosiadis, Brad Settlemyer, Gary Grider. SC ’21, November 14–19, 2021, St. Louis, MO, USA. Supersedes Carnegie Mellon University Parallel Data Lab Technical Report CMU-PDL-21-101, July 2021.
Abstract / PDF [1M] / Slides / Talk Video
- DeltaFS: A Scalable No-Ground-Truth Filesystem For Massively-Parallel Computing. Qing Zheng, Chuck Cranor, Greg Ganger, Garth Gibson, George Amvrosiadis, Brad Settlemyer, Gary Grider. Carnegie Mellon University Parallel Data Lab Technical Report CMU-PDL-21-101, July 2021.
Abstract / PDF [1M]
- Distributed Metadata and Streaming Data Indexing as Scalable Filesystem Services. Qing Zheng. Carnegie Mellon University School of Computer Science Ph.D. Dissertation, CMU-CS-21-103. February 2021.
Abstract / PDF [2.1M]
- Streaming Data Reorganization at Scale with DeltaFS Indexed Massive Directories. Qing Zheng, Charles D. Cranor, Ankush Jain, Gregory R. Ganger, Garth A. Gibson, George Amvrosiadis, Bradley W. Settlemyer, Gary Grider. ACM Transactions on Storage, Vol. 16, No. 4, Article 23. September 2020.
Abstract / PDF [2.1M]
- Mochi: Composing Data Services for High-Performance Computing Environments. Robert B. Ross, George Amvrosiadis, Philip Carns, Charles D. Cranor, Matthieu Dorier, Kevin Harms, Greg Ganger, Garth Gibson, Samuel K. Gutierrez, Robert Latham, Bob Robey, Dana Robinson, Bradley Settlemyer, Galen Shipman, Shane Snyder, Jerome Soumagne, Qing Zheng. Journal of Computer Science and Technology 35(1): 121–144 Jan. 2020.
Abstract / PDF [1.3M]
- Compact Filter Structures for Fast Data Partitioning. Qing Zheng, Charles D. Cranor, Ankush Jain, Gregory R. Ganger, Garth A. Gibson, George Amvrosiadis, Bradley W. Settlemyer, Gary A. Grider. Carnegie Mellon University Parallel Data Lab Technical Report CMU-PDL-19-104, June 2019.
Abstract / PDF[574K]
- Scaling Embedded In-Situ Indexing with DeltaFS. Qing Zheng, Charles D. Cranor, Danhao Guo, Gregory R. Ganger, George Amvrosiadis, Garth A. Gibson, Bradley W. Settlemyer, Gary Grider, Fan Guo. SC18, November 11-16, 2018, Dallas, Texas, USA.
Abstract / PDF [927K]
- Software-Defined Storage for Fast Trajectory Queries using a DeltaFS Indexed Massive Directory. Qing Zheng, George Amvrosiadis, Saurabh Kadekodi, Garth Gibson, Chuck Cranor, Brad Settlemyer, Gary Grider, Fan Guo. PDSW-DISCS 2017: 2nd Joint International Workshop on Parallel Data Storage and Data Intensive Scalable Computing Systems held in conjunction with SC17, Denver, CO, November 2017.
Abstract / PDF [1.25M]
- DeltaFS: Exascale File Systems Scale Better Without Dedicated Servers. Qing Zheng, Kai Ren, Garth Gibson, Bradley W. Settlemyer, Gary Grider. PDSW2015: 10th Parallel Data Storage Workshop, held in conjunction with SC15, Austin, TX, November 16, 2015.
Abstract / PDF [930K]
Acknowledgements
We thank the members and companies of the PDL Consortium: Amazon, Bloomberg LP, Datadog, Google, Intel Corporation, Jane Street, LayerZero Research, Meta, Microsoft Research, Oracle Corporation, Oracle Cloud Infrastructure, Pure Storage, Salesforce, Samsung Semiconductor Inc., and Western Digital for their interest, insights, feedback, and support.