ACTIVE DISKS: Remote Execution for
Network-Attached Storage
An important trend in the design of storage subsystems is a move toward
direct network attachment and increased intelligence at storage devices.
Network-attached storage offers the opportunity to offload file system
and storage management functionality from dedicated server machines
and execute many requests directly at storage devices without server
intervention. Raising the level of the storage interface above the simple
linear address space of SCSI allows more efficient operation at the
device and promises more scalable subsystems. This work takes this interface
one step further and suggests that allowing application-specific code
to be executed at storage devices on behalf of clients/servers can make
more effective use of device, client and interconnection resources and
considerably improve application I/O performance. Remote execution of
code directly at storage devices allows filter operations to be performed
close to the data; allows optimization of timing-sensitive transfers
by taking advantage of application-specific knowledge at the storage
device; allows management functions to be customized and updated without
requiring firmware upgrades; and makes possible complex or specialized
operations than a general-purpose storage interface would normally support.
Trends
The processing power available
on disk drives is rapidly increasing. Modern SCSI disks contain microprocessors
that are only three or four generations behind top-of-the-line host
processors. A high-end drive available from Quantum today is driven
by a 25 MHz Motorola 68020 along with a single specialized chip for
handling SCSI, servo, and disk functions. Improvements in chip technology
make it conceivable to include an integrated 100 MHz RISC core in the
same die space as the current ASIC and still leave room for the additional
cryptographic and network processing required by network-attached disks.
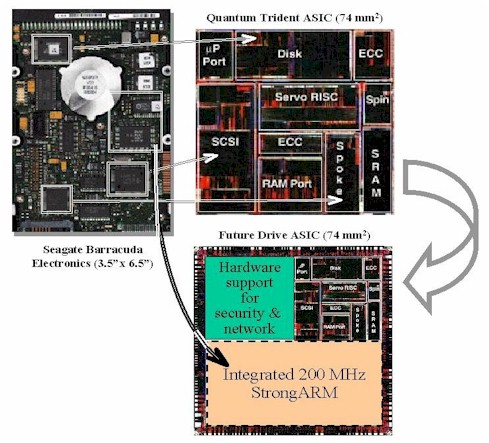
The graphic below shows how the electronics of the drive on the left
have shrunk into a single ASIC that includes all the basic drive functions.
By moving from the current 0.68 micron to a 0.35 micron silicon process,
we free up die area for additional networking and security functions
and make room for an embedded 200 MHz StrongARM to replace the microcontroller
in the original drive. All drive control is now combined into a single
chip with a significant amount of additional computing power.
 |
|
This diagram was created by photo-reducing an image of the existing
Trident ASIC, but chips similar to the one shown have been announced
by Siemens (Tri-Core -
100 MHz RISC core, up to 2 MB of memory, up to 500 MIPS within 2 years),
Cirrus Logic (3CI - ARM7 core,
moving to 200 MHz ARM9 core in the second generation), and Texas Instruments
(C27x -
150 MIPS in the first generation, 16 MB address space). |
This microprocessor is not involved
in the balance of the fastpath processing on the drive and will have
cycles to spare in normal operation. We propose Active Disks as a way
to take advantage of these cycles to provide value-added processing
directly at disks. Active Disks allow application-specific code to execute
inside the disk in order to reduce load on the network, offload processing
currently done by clients/servers, and enable novel functions that can
take advantage of closer knowledge of the disks' internal state than
a general storage interface can provide.
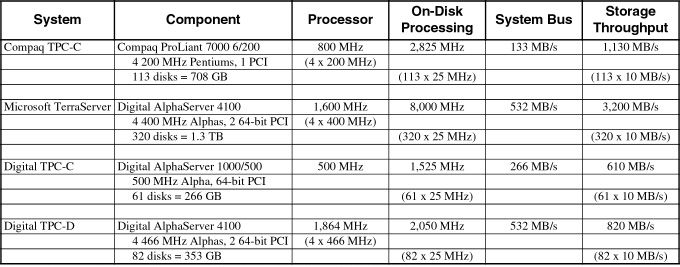 |
Table 1: If we estimate that current disk drives have the equivalent of 25 MHz of host processing speed available, large database systems today already contain more processing power on their combined disks than at the server processors. Assuming a reasonable 10 MB/s for sequential scans, we also see that the aggregate storage bandwidth is more than twice the backplane bandwidth of the machine in almost every case. Data from [TPC98] and [Barclay97]. |
With drive media rates at 20 MB/s
today (e.g. Seagate's Cheetah) and expected to reach 30 MB/s by the end of the decade,
the limiting factor in disk I/O will no longer be the drive mechanics,
but the “network” latency to access the devices and the processing
required at clients/servers to manage the I/O. Processing that can be
performed cheaply at the disks will offload the other system components
and can significantly improve overall user-visible performance. The
table above shows that even with relatively low-powered processors (assuming
the 25 MHz microprocessors already in drives today) and low drive bandwidths
(a modest 10 MB/s) the aggregate processing power available on the disks
attached to most large database servers already exceeds that of the
server CPUs. Even more importantly, the I/O backplanes of these machines
cannot keep up with the total throughput available from the storage
devices. Allowing processing directly at disks greatly increases total
computational power and allows application-level throughput at the level
of what the storage devices can provide.
Opportunity
The most promising candidate applications for Active Disks will be able to leverage the parallelism in highly concurrent workloads by striping across a large number of drives. The ability to leverage the processing power of tens or 100s of disks can more than compensate for the lower relative MIPS of single drives compared to host processors. On-drive computations should be localized to small amounts of data, essentially performing a small amount of processing as data “streams past” from the disk media on its way to the network. Remote functions should have small code/cycle footprint per byte processed in order to keep data moving at near media rates and allow scheduling of remote computation with normal drive activity. The ability to access internal drive state and take advantage of on-drive scheduling mechanisms enables a range of storage management and “real time” functions that are not possible with today's interfaces.
We have identified a set of five categories of applications that may benefit from Active Disks, each of which take advantage of a different set of on-drive features:
- filtering - search, association matching, sort
- batching - collective I/O
- real-time - video server, streaming audio
- storage management - backup, layout optimization
- specialized support - locks, “transactions”
Applications - Data Mining
We have experimented with a number of applications in data mining and multimedia that could benefit from an Active Disk architecture.
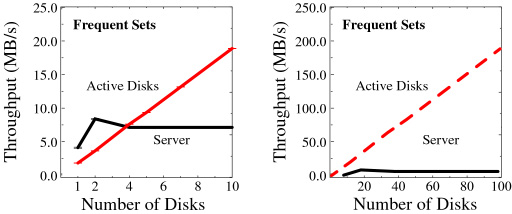
The first application we looked at is association rule discovery in
point-of-sale data. The purpose of the application is to extract rules
of the form “if a customer purchases item A and B, then they are
also likely to purchase item X” which can be used for store layout
or inventory decisions. The computation is done in several passes, first
determining the items that occur most often in the transactions (the 1-itemsets) and then using this information to generate pairs
of items that occur often (2-itemsets) and larger groupings (k-itemsets).
For the Active Disks system, the counting portion of each phase is performed
directly at the drives. The server produces the list of candidate k-itemsets
and provides this list to each of the disks. Each disk counts its portion
of the transactions locally, and returns these counts to the server.
The server then combines these counts and produces a list of candidate
(k+1)-itemsets which are sent back to the disks. This application reduces
an arbitrarily large number of transactions in a database into a single,
variably-sized set of summary statistics - the itemset counts - that
can be used to determine relationships in the data.
 |
|
 |
|
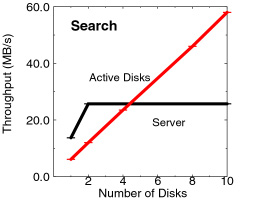
Our second application is an implementation of nearest- neighbor search
in a high- dimensionality database. We determine the k items
in a database of loan records that are closest to a particular input
item. For the Active Disk system, all the comparisons are done directly
at the drives. The server sends the target record to each of the disks
which determine the k closest records in their portions of the
database. These lists are then combined to determine the overall closest
records. Again, we see the traditional server bottleneck at a low number
of disks while the Active Disk system continues to scale to more than
2x faster with only 10 disks. For high- dimensionality data, traditional
indices lose much of their effectiveness and “brute force”sequential
scanning, which Active Disks are particularly good at, is competitive
with more complex methods using high-dimensional indices. |
Applications - Multimedia
For image processing, we looked at an application that detects edges
in a set of grayscale images. We use real images from IBM Almaden's
CattleCam and attempt to detect cows in the landscape above San Jose.
The application processes a set of 256 KB images and returns only the
edges found in the data using a fixed 37 pixel mask. The intent is to
model a class of image processing applications where only a particular
set of features (e.g. the edges) in an image are important, rather than
the entire image. This includes tracking, feature extraction, and positioning
applications that operate on only a small subset of the original images
data. This application is significantly more computation-intensive than
the comparisons and counting of the data mining applications.
 |
|
Using the Active Disks system, edge detection for each image is performed
directly at the drives and only the edges are returned to the server.
A request for the raw image at the left returns only the data on the right,
which can be represented much more compactly. |
Our second image processing application performs the image registration
portion of the processing of an MRI brain scan analysis. Image registration
determines the set of parameters necessary to register (rotate and translate)
an image with respect to a reference image in order to compensate for
movement of the subject during scanning. The application processes a
set of images and returns the registration parameters for each image.
This application is the most computationally intensive of the ones studied
because the algorithm includes two FFT computations. For the Active
Disks system, this application operates similarly to the edge detection.
The reference image is provided to all the drives and the registration
for each image is calculated directly at the drives with only the final
parameters returned to the server.
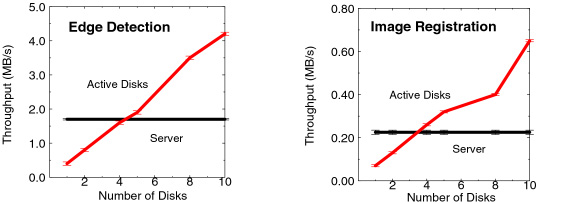 |
|
The scaling is as before, with the server becoming bottlenecked after
about four disks, while the Active Disk system continues to scale. We
also see that the image processing applications are much more computationally
intensive than the data mining applications, achieving only 4.5 MB/s
and 650 KB/s of aggregate throughput with ten Active Disks. This is
far below the aggregate bandwidth possible from the media, but the computation
power of the Active Disks still moves it ahead of the server by a margin
of more than 2x. |
Additional Applications
The existence of an execution environment at the drive makes it possible to provide management functions that are either more complex than drive firmware would normally allow or that are customized to the environment in which the drive is installed. For example, a backup function that took into account the configuration and workload patterns of a specific environment might be more efficient than a function provided in the drive firmware that had to support all possible environments and requirements. Having such management functions operate as remote programs also allows them to be updated to extended without rewriting the entire drive firmware. Possible management functions include backup; layout optimization based on filesystem- or application- specific knowledge, or on usage patterns observed at the drive; defragmentation; and reconfiguration.
As the use of multimedia becomes more widespread, there are a number of applications that require strict performance guarantees from storage systems. In existing systems, the accepted way to guarantee bandwidth is by having significant over-capacity in the system to ensure that peak requirements can be met. Applications which have soft real-time requirements, such as a streaming video display seeking to minimize jitter, require that specific deadlines be met, but also have properties that allow some flexibility. For example, an MPEG compressed movie has variable bandwidth requirements (due to non-uniform compression) which must usually be specified at the maximum rate to ensure delivery. It is also possible to drop frames - particularly I and B intermediate frames without affecting the display quality, as long as enough frames get through. Active Disks allow a video application to take advantage of these properties to schedule its use of storage and smooth its requirements, thereby allowing more efficient use of resources.
Specialized functions that require
specific semantics not normally provided by drives can be provided by
remote functions on Active Disks. This allows functionality specialized
to a particular environment or usage pattern to be executed where the
semantics are most efficiently implemented, rather than requiring additional
overhead in the higher levels of the system. Examples include a READ/MODIFY/WRITE operation or an atomic CREATE that would
both create a new file object and update the corresponding directory
object, for optimization of higher-level filesystems such as NFS on
NASD [Gibson97a]
Mechanisms
One of the important questions for a remote execution system is what programming model is provided for user-defined functions. A well-defined and limited set of interfaces such as those provided by packet filters or SQL allow control over the safety and (to some extent) the efficiency of user-provided functions, but also limit the richness of functions that can be implemented. Providing a type-safe programming language and depending on a combination of compile-time and run-time checks provides greater flexibility, but requires careful design of the system interfaces allowed to user-defined functions to prevent holes in the safety mechanism [McGraw97] and may put a significant cost on the run-time system (e.g. Java ). Object-level editing allows the insertion of run-time safety checks into compiled programs from any source language, but imposes a translation cost, a possibly significant run-time cost and again requires very careful design of the system interfaces [Lucco93, Software Fault Isolation]. A system such as proof-carrying code moves the burden of ensuring safety from the run-time system to the code producer [Necula96] , but may limit the complexity of the programs that can be expressed.
Our work on Active Disks builds on our previous work in Network-Attached Secure Disks (NASD) which proposes making disks first-class citizens on the general-purpose network [Gibson97] and raising the storage interface above the simple block-level protocol of SCSI [Gibson97a] . Both the “object oriented” (rather than block oriented) interface to storage and the security system of NASD provide a solid base for Active Disk functions. These allow access and control at a coarse enough granularity that drives and on-drive functions can operate relatively autonomously, while retaining control and basic policy decisions in a central set of “file managers”.
Beyond this basic interface, there are a there are a number of functions
that make Active Disks more powerful and flexible. These must include
this basic filesystem API, as provided to regular clients, as well as
a form of input/output with the host application. More advanced functions
might benefit from asynchronous “callbacks” with the host,
some form of long-term state at the drive, the ability to specify processing
deadlines, including perhaps real-time guarantees, and admission control
to manage drive functions. In order to take full advantage of optimizations
at the drive, the ability for remote functions to inquire about the
state of the cache and block layout, and to control caching and layout
through a local interface would all be beneficial. Finally, some applications
(storage management in particular) might desire the capability to open
communication with 3rd parties (e.g. a tape device). The relative costs
and benefits of these different functions are a central open issue in
the design of an Active Disk environment.
Publications
- Active Disks for Large-Scale Data Processing. IEEE
Computer, June 2001.
Abstract / PDF [722K]
- Active Disk Architecture for Databases. Technical Report
CMU-CS-00-145, May 2000.
Abstract / PDF [201K]
- Data Mining on an OLTP System (Nearly) for Free. Proceedings
of the 2000 ACM SIGMOD International Conference on Management of Data,
Dallas, TX, May 2000. Supercedes CMU SCS Technical Report CMU-CS-01-151.
Abstract / PDF [171K]
- Active Disks - Remote Execution for Network-Attached Storage. Technical Report CMU-CS-99-177, Doctoral Dissertation.
Pittsburgh, PA, November 1999.
Abstract / PDF [2.7M]
- Active Storage For Large-Scale Data Mining and Multimedia. Proceedings of the 24th International Conference on Very Large
Databases (VLDB '98), New York, NY, August 1998.
Abstract / PDF [231K] / talk
- Active Disks: Remote Execution for Network-Attached Storage. CMU-CS-97-198, December 1997.
Abstract / PDF [123K]
Talks
- "Active Disks For Databases," NSIC/NASD Workshop on Network
Storage for Databases: Asset, Apathy, or Albatross?, Millbrae,
CA, August 17, 1999.
pdf / workshop site
- "Active Disks - Remote Execution for Network-Attached Storage," Systems Seminar, University of California - Berkeley,
Berkeley, CA, October 8, 1998.
pdf / seminar site
- "Active Storage For Large-Scale Data Mining and Multimedia," 24th
International Conference on Very Large Databases (VLDB '98), Vision Paper, New York, NY, August 24, 1998.
pdf / conference site
- "Active Disks For Large-Scale Data Mining and Multimedia," NSIC/NASD
Workshop: What is to be done with lots more computing inside storage?,
Oakland, CA, June 8, 1998.
pdf / workshop site
- "Active Disks For Large-Scale Data Mining and Multimedia," SIGMOD
'98 - Data Mining and Knowledge Discovery Workshop, Seattle,
WA, June 5, 1998.
pdf / workshop site
- "Active Storage For Large-Scale Data Mining and Multimedia," Center
for Automated Learning and Discovery (CALD) Seminar, Carnegie
Mellon University, April 3, 1998.
pdf / CALD site
- "Active Disks - A Case for Remote Execution in Network-Attached
Storage," Parallel Data Systems Retreat, Nemacolin, PA,
October 29, 1997.
ps / pdf / retreat site
Acknowledgements
We thank the members and companies of the PDL Consortium: Amazon, Google, Hitachi Ltd., Honda, Intel Corporation, IBM, Meta, Microsoft Research, Oracle Corporation, Pure Storage, Salesforce, Samsung Semiconductor Inc., Two Sigma, and Western Digital for their interest, insights, feedback, and support.