FATES DATABASE STORAGE
Database Query Execution with Fates
by Jiri Schindler, Minglong Shao, Steve Schlosser, Anastassia Ailamaki & Greg Ganger
Current database systems use data layouts that can exploit unique features of only one level of the memory hierarchy (cache/main memory or on-line storage). Such layouts optimize for the predominant access pattern of one workload (e.g., DSS), while trading off performance of another workload type (e.g., OLTP). Achieving efficient execution of different workloads without this trade-off or the need to manually re-tune the system for each workload type is still an unsolved problem. The “Fates” database system project answers this challenge.
 The
primary goal of the project is to achieve efficient execution of compound
database workloads at all levels of a database system memory hierarchy.
By leveraging unique characteristics of devices at each level, the Fates
database system can automatically match query access patterns to the
respective device characteristics, which eliminates the difficult and
error-prone task of manual performance tuning.
The
primary goal of the project is to achieve efficient execution of compound
database workloads at all levels of a database system memory hierarchy.
By leveraging unique characteristics of devices at each level, the Fates
database system can automatically match query access patterns to the
respective device characteristics, which eliminates the difficult and
error-prone task of manual performance tuning.
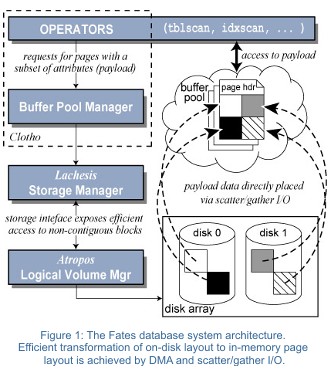
Borrowing from the Greek mythology of The Three Fates – Clotho, Lachesis, and Atropos – who spin, measure, and cut the thread of life, the three components of our database system (bearing the Fates’ respective names) establish proper abstractions in the database query execution engine. These abstractions cleanly separate the functionality of each component (described below) while allowing efficient query execution along the entire path through the database system.
The main feature of the Fates database system is the decoupling of the in-memory data layout from the on-disk storage layout. Different data layouts at each memory hierarchy level can be tailored to leverage specific device characteristics at that level. An in-memory page layout can leverage L1/L2 cache characteristics, while another layout can leverage characteristics of storage devices. Additionally, the storage-device-specific layout also yields efficient I/O accesses to records for different query access patterns. Finally, this decoupling also provides flexibility in determining what data to request and keep around in main memory.
Traditional database systems are forced to fetch and store unnecessary data as an artifact of a chosen data layout. The Fates database system, on the other hand, can request, retrieve, and store just the needed data, catering to the needs of a specific query. This conserves storage device bandwidth, memory capacity, and avoids cache pollution—all of which improves query execution time.
Scatter/gather I/O facilitates efficient transformation from one layout into another and creates an organization amenable to the individual query needs on-the-fly. In addition to eliminating expensive data copies, these I/Os match explicit storage device characteristics, ensuring efficient execution at the storage device. Finally, thanks to proper abstractions established by each Fate, other database system components (e.g., the query optimizer or the locking manager) remain unchanged.
Clotho
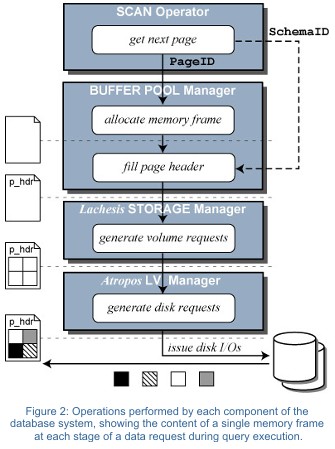 Clotho
ensures efficient query execution at the cache/main-memory level and
figures at the inception of a request for particular data. When the
data desired by a query is not found in the buffer pool, Clotho creates
a skeleton of a page in a memory frame describing what data is needed
and how to lay it out.
Clotho
ensures efficient query execution at the cache/main-memory level and
figures at the inception of a request for particular data. When the
data desired by a query is not found in the buffer pool, Clotho creates
a skeleton of a page in a memory frame describing what data is needed
and how to lay it out.
The page layout builds upon a cache-friendly layout, called PAX [1], which groups data into minipages, where each minipage contains the data of only a single attribute (table column). Aligning records on cache line boundaries within each minipage and taking advantage of cache prefetching logic improves the performance of scan operations without sacrificing full-record access.
Clotho adjusts the position and size of each minipage within the frame. It matches the minipage size to the (multiple of) block size of the storage device, provided by Atropos, and decides which minipages to store within a single page based on the needs of a given query. Hence, minipages within a single memory frame contain only the attributes needed by that query. The remaining attributes constituting the full record, but not needed by the query, are never requested.
The skeleton page inside the memory frame includes a header that lists
the attributes and the range of records to be retrieved from the storage
device and stored in that frame. Clotho marks the set of attributes
needed by the query in the page header (i.e., the payload) and identifies
the range of records to be put
into the page. Hence, the page header serves as a
request from Clotho to Lachesis to retrieve the desired data.
Lachesis
The Lachesis database storage manager handles the mapping and access to minipages located within the LBNs of on-line storage devices. Utilizing storage device-provided performance characteristics and matching query access patterns (e.g., sequential scan) to these hints, Lachesis constructs efficient I/Os. It also sets scatter/gather I/O vectors that allow direct placement of individual minipages to proper memory frames without unnecessary memory copies.
Explicit relationships between individual logical blocks (LBNs), established
by Atropos, allow Lachesis to devise a layout that groups together a
set of related minipages. This grouping ensures that all attributes
belonging to the same set of records can be accessed in parallel, while
a particular attribute can be accessed with efficient sequential I/Os.
The relationships between LBNs serve as hints that let Lachesis construct
I/Os that Atropos can execute efficiently.
The layout and content of each minipage is transparent to both Lachesis
and Atropos. Lachesis merely decides how to map each minipage to LBNs
to be able to construct a batch of efficient I/Os. Atropos in turn,
cuts these batches into individual disk I/Os comprising the exported
logical volume. It does not care where the data will be placed in memory;
this is decided by the scatter/gather I/O vectors set up by Lachesis.
Atropos
Atropos is a disk array logical volume manager that offers efficient access in both row- and column-major orders. For database systems, this translates into efficient access to complete records as well as scans of an arbitrary number of table attributes. By utilizing features built into disk firmware and a new data layout, Atropos delivers the aggregate bandwidth of all disks for accesses in both majors, without penalizing small random I/O accesses.
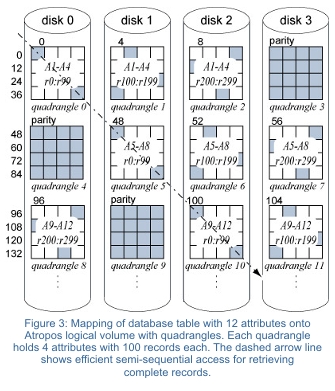 The
basic allocation unit in Atropos is the quadrangle, which is a collection
of logical volume LBNs. A quadrangle spans the entire track of a single
disk along one dimension and a small number of adjacent tracks along
the other dimension. Each successive quadrangle is mapped to a different
disk, much like a stripe unit of an ordinary RAID group. Hence, the
RAID 1 or RAID 5 data protection schemes fit the quadrangle layout naturally.
The
basic allocation unit in Atropos is the quadrangle, which is a collection
of logical volume LBNs. A quadrangle spans the entire track of a single
disk along one dimension and a small number of adjacent tracks along
the other dimension. Each successive quadrangle is mapped to a different
disk, much like a stripe unit of an ordinary RAID group. Hence, the
RAID 1 or RAID 5 data protection schemes fit the quadrangle layout naturally.
Atropos stripes contiguous LBNs across quadrangles mapped to all disks. This provides aggregate streaming bandwidth of all disks for table accesses in column-major order (e.g., for single attribute scans). With quadrangle “width” matching disk track size, sequential accesses exploits the high efficiency of track-based access [2].
Accesses in the other major order (i.e. row-major order), called semi-sequential, proceed to LBNs mapped diagonally across a quadrangle, with each LBN on a different track. Issuing all requests together to these LBNs allows the disk’s internal scheduler to service the request with the smallest positioning cost first, given the current disk head position. Servicing the remaining requests does not incur any other positioning overhead thanks to the diagonal layout. Hence, this semi-sequential access pattern is much more efficient than reading some randomly chosen LBNs spread across the set of adjacent tracks of a single quadrangle.
Semi-sequential quadrangle access is used for retrieving minipages with all attributes comprising a full record. If the number of minipages/attributes does fit into a single quadrangle, the remaining minipages are mapped to a quadrangle on a different disk. Using this mapping method, several disks can be accessed in parallel to retrieve full records efficiently.
Summary
Fates is the first database system that leverages the unique characteristics of each level in the memory hierarchy. The decoupling of data layouts at the cache/main-memory and on-line storage levels is possible thanks to carefully orchestrated interactions between each Fate. Properly designed abstractions that hide specifics, yet allow the other components to take advantage of their unique strengths achieve efficient query execution at all levels of the memory hierarchy.
References
- A. Ailamaki, D. J. DeWitt, M. D. Hill, M. Skounakis. Weaving Relations for Cache Performance. Proc. of VLDB, 169-180. Morgan Kaufmann, 2001.
- J. Schindler, J. L. Griffin, C. R. Lumb, G.R. Ganger. Track-aligned Extents: Matching Access Patterns to Disk Drive Characteristics. Conference on File and Storage Technologies, 259-274. Usenix Association, 2002.