Survivable Storage Systems
by Greg Ganger & Joan Digney
(reprinted from the PDL Packet,
Fall 2002)
Digital information is a critical resource. We need storage systems
to which users can entrust critical information, ensuring that the data
persists, is accessible, cannot be destroyed, and is kept confidential.
A survivable storage system provides these guarantees, despite failures
and malicious compromises of storage nodes, client systems, and user
accounts. This article reviews two PDL projects that address this need:
the PASIS project focuses on surviving attacks on storage servers, and
self-securing storage focuses on surviving intrusions into client systems.
PASIS
Survivable systems operate from the fundamental design thesis that no individual service, node, or user can be fully trusted; having some compromised entities is viewed as a common case rather than an exception [1]. Survivable storage systems must therefore encode and distribute data across independent storage nodes, entrusting data persistence to sets of nodes rather than to individual nodes. Further, if confidentiality is required, unencoded data should not be stored directly on individual storage nodes; otherwise, compromising a single storage node would let an attacker bypass access-control policies. With well-chosen encoding and distribution schemes, significant increases in availability, confidentiality, and integrity are possible.
Many research groups now explore the design and implementation of such survivable storage systems. These systems build on mature technologies from decentralized storage systems and also share a common high-level architecture (Figure 1). In fact, development of survivable storage with the same basic architecture was pursued over 15 years ago. As it was then, the challenge now is to achieve acceptable levels of performance and manageability. Moreover, a means to evaluate survivable storage systems is needed.
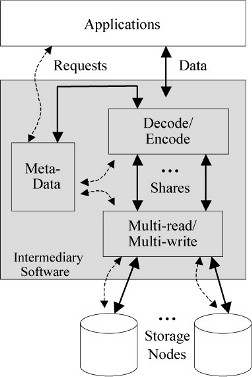
Figure 1: Generic decentralized storage architecture.
Intermediary software translates the applications’ unified view
of storage to the decentralized reality. Encoding transforms blocks
into shares (decoding does the reverse). Sets of shares are read from
(written to) storage nodes. Intermediary software may run on clients,
leader storage nodes, or at some point in between.
One key to maximizing survivable storage performance is mindful selection of the data distribution scheme. A data distribution scheme consists of a specific algorithm for data encoding & partitioning and a set of values for its parameters. There are many algorithms applicable to survivable storage, including encryption, replication, striping, erasure-resilient coding, secret sharing, and various combinations. Each algorithm has one or more tunable parameters, such as the number of fragments generated during a write and the subset needed for a read. The result is a large toolbox of possible schemes, each offering different levels of performance (throughput), availability (probability that data can be accessed), and security (effort required to compromise the confidentiality or integrity of stored data). For example, replication provides availability at a high cost in network bandwidth and storage space, whereas short secret sharing provides availability and security at lower storage and bandwidth cost but higher CPU utilization. Likewise, selecting the number of shares required to reconstruct a secret-shared value involves a trade-off between availability and confidentiality: if more machines are compromised to steal a secret, then more must be operational to provide it legitimately.
No single data distribution scheme is right for all systems. Instead, the right choice for any particular system depends on an array of factors, including expected workload, system component characteristics, and desired levels of availability and security. Unfortunately, most system designs appear to involve an ad hoc choice, often resulting in a substantial performance loss due to missed opportunities and over-engineering.
The PASIS project is developing a better approach to selecting the
data distribution scheme. At a high level, this new approach consists
of three steps: enumerating possible data distribution schemes (<algorithm,
parameters> pairs), modeling the consequences of each scheme, and
identifying the best-performing scheme for any given set of availability
and security requirements. The surface shown in Figure 2 illustrates
one result of the approach. Generating such a surface requires codifying
each dimension of the trade-off space such that all data distribution
schemes fall into a total order. The surface serves two functions: (1)
it enables informed trade-offs among security, availability, and performance;
and (2) it identifies the best-performing scheme for each point in the
trade-off space. Specifically, the surface shown represents the performance
of the best-performing scheme that provides at least the corresponding
levels of availability and security. Many schemes are not best at any
of the points in the space and, as such, are not visible on the surface.
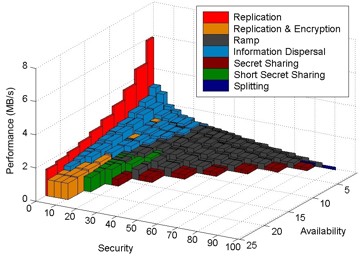
Figure 2: Data distribution scheme
selection surface plotted in trade-off space.
Wylie et al. [2] demonstrate the feasibility and importance of careful data distribution scheme choice. The results show that the optimal choice varies as a function of workload, system characteristics, and the desired levels of availability and security. Minor (~2x) changes in these determinants have little effect, which means that the models need not be exact to be useful. Large changes, which would correspond to distinct systems, create substantially different trade-off spaces and best choices. Thus, failing to examine the trade-off space in the context of one's system can yield both poor performance and unfulfilled requirements.
Of course, the research is not done. We continue to refine the configuration
approach, exploring useful ways to approximate security metrics, and
to push the boundaries of efficient decentralization.
Self-Securing Storage
Desktop compromises and misbehaving insiders are a fact of modern computing. Once an intruder infiltrates a system, he can generally gain control of all system resources, including its storage access rights (complete rights, in the case of an OS accessing local storage). Crafty intruders can use this control to hide their presence, weaken system security, and manipulate sensitive data. Because storage acts as a slave to authorized principals, evidence of such actions can generally be hidden. In fact, so little of the system state is trustworthy after an intrusion that the common "recovery" approach starts with reformatting storage.
Self-securing storage is an exciting new technology for enhancing intrusion
survival by enabling the storage device to safeguard data even when
the client OS is compromised. It capitalizes on the fact that storage
servers (whether file servers, disk array controllers, or even IDE disks)
run separate software on separate hardware. This opens the door to server-embedded
security that cannot be disabled by any software (even the OS) running
on client systems as shown in Figure 3. Of course, such servers have
a narrow view of system activity, so they cannot distinguish legitimate
users from clever impostors. But, from behind the thin storage interface,
a self-securing storage server can actively look for suspicious behavior,
retain an audit log of all storage requests, and prevent both destruction
and undetectable tampering of stored data. The latter goals are achieved
by retaining all versions of all data; instead of over-writing old data
when a write command is issued, the storage server simply creates a
new version and keeps both. Together with the audit log, the server-retained
versions represent a complete history of system activity from the storage
system’s point of view.
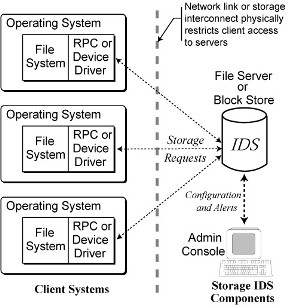
Figure 3: The compromise independence of self-securing
storage. The storage interface provides a physical boundary between
a storage server and client OSes. Note that this samd picture works
for block protocols, such as SCSI or IDE/ATA, and distributed file system
protocols such as NFS or CIFS.
Strunk et al. [3] introduced self-securing storage and evaluated its feasibility. It was demonstrated that, under a variety of workloads, a small fraction of the capacity of modern disk drives is sufficient to hold several weeks of complete storage history. With a prototype implemen-tation, it was also demonstrated that the performance overhead of keeping the complete history is small. Two recent papers [4,5], delve more deeply into how self-securing storage can improve intrusion survival by safeguarding stored data and providing new information regarding storage activities before, during, and after the intrusion. Specifically, self-securing storage contributes in three ways:
First, a self-securing storage server can assist with intrusion detection by watching for suspicious storage activity [4]. By design, a storage server sees all requests and stored data, so it can issue alerts about suspicious storage activity as it happens. Such storage-based intrusion detection can quickly and easily notice several common intruder actions, such as manipulating system utilities (e.g., to add backdoors) or tampering with audit log contents (e.g., to conceal evidence). Such activities are exposed to the storage system even when the client system’s OS is compromised.
Second, after an intrusion has been detected and stopped, self-securing storage provides a wealth of information to security administrators who wish to analyze an intruder's actions. In current systems, little information is available for estimating damage (e.g., what information the intruder might have seen or what data was modified) and determining how he gained access. Because intruders can directly manipulate data and metadata in conventional systems, they can remove or obfuscate traces of such activity. With self-securing storage, intruders lose this ability -- in fact, attempts to do these things become obvious red flags for intrusion detection and diagnosis efforts. Although technical challenges remain in performing such analyses, they will start with much more information than forensic techniques can usually extract from current systems.
Third, self-securing storage can speed up and simplify the intrusion recovery process. In today's systems, full recovery usually involves reformatting, reinstalling the OS from scratch, and loading user data from back-up tapes. These steps are taken to remove backdoors or Trojan horses that may have been left behind by the intruder. Given server-maintained versions, on the other hand, an administrator can simply copy-forward the pre-intrusion state (both system binaries and user data) in a single step. Further, all work done by the user since the security breach remains in the history pool, allowing incremental (albeit potentially dangerous) recovery of important data.
In continuing work, we are exploring administrative interfaces for
configuring and utilizing the features of self-securing storage. We
will also explore how they complement security functionality embedded
in other devices, such as network interface cards and network switches/routers.
References
[1] Wylie, J., et al. Survivable
Information Storage Systems. IEEE Computer, Aug 2000.
[2] Wylie, J., et al. Selecting
the Right Data Distribution Scheme for a Survivable Storage System.
CMU SCS Technical Report CMU-CS-01-120, May 2001.
[3] Strunk, J.D., et al. Self-Securing
Storage: Protecting Data in Compromised Systems. Proc. of the 4th
Symposium on Operating Systems Design and Implementation, October, 2000.
[4] Pennington, A., et al. Storage-based
Intrusion Detection: Watching Storage Activity For Suspicious Behavior.
CMU SCS Technical Report CMU-CS-02-179, September 2002.
[5] Strunk, J.D., et al. Intrusion
Detection, Diagnosis, and Recovery with Self-Securing Storage. CMU
SCS Technical Report CMU-CS-02-140, May 2002.