ATLAS: Analysis of Traces from Los Alamos Supercomputers
 At the Los Alamos National Laboratory (LANL), computing clusters are monitored closely to ensure their availability. Terabytes of data are collected every day on each cluster’s operation from several sources: job scheduler logs, sensor data, and file system logs, among others. Project Atlas aims to analyze and model the operation of LANL clusters, and use these models to develop techniques that improve clusters’ operational efficiency.
At the Los Alamos National Laboratory (LANL), computing clusters are monitored closely to ensure their availability. Terabytes of data are collected every day on each cluster’s operation from several sources: job scheduler logs, sensor data, and file system logs, among others. Project Atlas aims to analyze and model the operation of LANL clusters, and use these models to develop techniques that improve clusters’ operational efficiency.
Trace Analysis
One of the current targets of Atlas is the characterization of diversity in cluster workloads and its impact on research results. Did you know that the most popular cluster workload trace was released by Google in 2012 and has been used in more than 450 publications already? Due to the scarcity of other data sources, however, researchers have started to overfit their work to the Google trace’s characteristics. We have been able to demonstrate this overfitting by introducing four new traces from two private clusters of a hedge fund firm (HedgeFund) and two LANL clusters. Our analysis shows that the HedgeFund workloads, consisting of data analytics jobs expected to be more closely related to the Google workload, display more similarity to LANL’s HPC cluster workloads (see Figure 1 for examples). Overall, our analysis results show that the new traces differ from the Google trace in substantive ways, suggesting that additional traces should be considered when evaluating the generality of new research. Through project Atlas, we plan to aid the community in moving forward by publicly releasing these and additional future traces. Furthermore, we plan to continue challenging workload assumptions used widely in the literature through our analysis of new datasets from LANL and other organizations.
|
Figure 1: CDFs of job size and duration across the Google, LANL, and HedgeFund traces. |
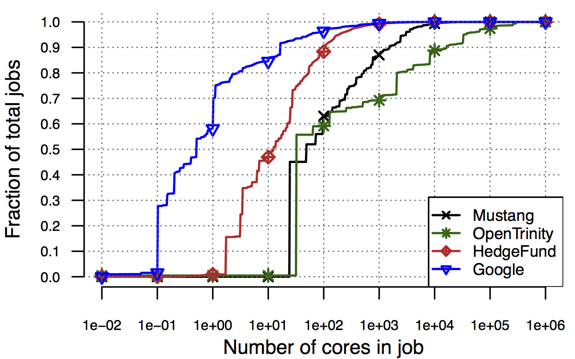
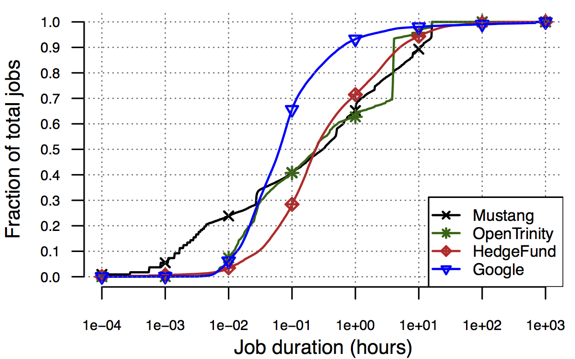
Workload Modeling
LANL jobs terminate with three possible statuses; a job can be successful, cancelled, or timed out. Job cancellations are triggered by a user or as the result of a failure in software or hardware. Job timeouts occur when the user-provided time limit is reached, which results in the job getting killed, and they occur often because users are motivated to issue jobs with small time limits, as those are generally prioritized by the scheduler. Our analysis of LANL job logs from the Mustang and Trinity clusters shows that a large number of CPU hours are allocated to jobs that are eventually cancelled or time out. The majority of this CPU time is very unlikely to be wasted. Our goal is to use cluster traces from a variety of data sources to build models that accurately predict job outcomes ahead of time. Such information could be leveraged by the scheduler, or even the users when deciding the frequency with which job state should be persisted to disk, in order to recover from a job termination and continue computing without repeating lost work.
People
FACULTY
George Amvrosiadis
Greg Ganger
Chuck Cranor
Garth Gibson
GRAD STUDENTS
Jun Woo Park
Michael Kuchnik
Bryan Hooi
PARTNERS
Los Alamos National Laboratory: Elisabeth Baseman, Nathan DeBardeleben
Software Engineering Institute: Scott McMillan
Publications
- CMU-PDL-19-103: This is Why ML-driven Cluster Scheduling Remains Widely Impractical. Michael Kuchnik, Jun Woo Park, Chuck Cranor, Elisabeth Moore, Nathan DeBardeleben, George Amvrosiadis. Carnegie Mellon University Parallel Data Lab Technical Report CMU-PDL-19-103, May 2019.
Abstract / PDF [715K]
- On the Diversity of Cluster Workloads and its Impact on Research Results. George Amvrosiadis, Jun Woo Park, Gregory R. Ganger, Garth A. Gibson, Elisabeth Baseman, Nathan DeBardeleben. 2018 USENIX Annual Technical Conference (ATC '18), Boston, MA, July 11-13, 2018.
Abstract / PDF [285K]
- Bigger, Longer, Fewer: What do cluster jobs look like outside Google? George Amvrosiadis, Jun Woo Park, Gregory R. Ganger, Garth A. Gibson, Elisabeth Baseman, Nathan DeBardeleben. Carnegie Mellon University Parallel Data Lab Technical Report CMU-PDL-17-104, October 2017.
Abstract / PDF [360K]
Acknowledgements
We thank the members and companies of the PDL Consortium: Amazon, Bloomberg LP, Datadog, Google, Intel Corporation, Jane Street, LayerZero Research, Meta, Microsoft Research, Oracle Corporation, Oracle Cloud Infrastructure, Pure Storage, Salesforce, Samsung Semiconductor Inc., and Western Digital for their interest, insights, feedback, and support.