NASD: A Parallel Filesystem for NASD Clusters
To fully exploit the potential bandwidth in a NASD system, higher-level filesystems should be able to make large, parallel requests to files striped across multiple NASD drives. A layered approach allows the filesystem to manage a “logical” object store as provided by the Cheops storage management system which redirects clients to the underlying component NASD objects. Our prototype system implements a Cheops client library to translate application requests and manage both levels of capabilities across multiple NASD drives. A separate Cheops storage manager manages mappings for striped objects and supports concurrency control for multi-disk accesses.
To provide support for parallel applications, we implemented a simple parallel filesystem, NASD PFS, which offers the SIO low-level parallel filesystem interface and employs Cheops as its storage management layer. We used MPICH for communications within our parallel applications, while Cheops uses the DCE RPC mechanism required by our NASD prototype.
To evaluate the performance of Cheops, we used a parallel data mining system that discovers association rules in sales transactions. The application’s goal is to discover rules of the form “if a customer purchases milk and eggs, then they are also likely to purchase bread” to be used for store layout or inventory decisions. It does this in several full scans over the data, first determining the items that occur most often in the transactions (the 1-itemsets), then using this information to generate pairs of items that occur most often (2-itemsets) and then larger groupings (k-itemsets) in subsequent passes. Our parallel implementation avoids splitting records over 2 MB boundaries and uses a simple round-robin scheme to assign 2 MB chunks to clients. Each client is implemented as four producer threads and a single consumer. Producer threads read data in 512 KB requests (which is the stripe unit for Cheops objects in this configuration) and the consumer thread performs the frequent sets computation, maintaining a set of itemset counts that are combined at a single master client. This threading maximizes overlapping and storage utilization.
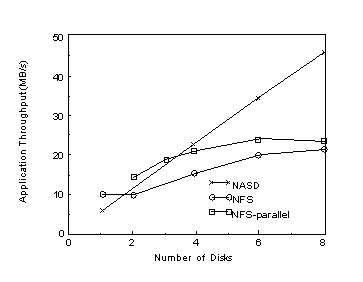
Figure 1: Scaling of a parallel data mining application. The aggregate bandwidth computing frequent sets from 300 MB of sales transactions is shown. The NASD line shows the bandwidth of n clients reading from a single NASD PFS file striped across n drives and scales linearly to 45 MB/s. All NFS configurations show the maximum achievable bandwidth with the given number of disks, each twice as fast as a NASD, and up to 10 clients spread over two OC-3 ATM links. The comparable NFS line shows the performance all the clients reading from a single file striped across n disks on the server and bottlenecks near 20 MB/s. This configuration causes poor read-ahead performance inside the NFS server, so we add the NFS-parallel line where each client reads from a replica of the file on an independent disk through the one server. This configuration performs better than the single file case, but only raises the maximum bandwidth from NFS to 22.5 MB/s.
Figure 1 shows the bandwidth scalability of the most I/O bound of the phases (the generation of 1-itemsets) processing a 300 MB sales transaction file. A single NASD provides 6.2 MB/s per drive and our array scales linearly up to 45 MB/s with 8 NASD drives. In comparison, we also show the bandwidth achieved when NASD PFS fetches from a single higher-performance traditional NFS file instead of a Cheops NASD object. We show two application throughput lines for the NFS server. The line marked NFS-parallel shows the performance of each client reading from an individual file on an independent disk and achieves performance up to 22.5 MB/s. The results show that the NFS server (with 35+ MB/s of network bandwidth, 54 MB/s of disk bandwidth and a perfect sequential access pattern on each disk) loses much of its potential performance to CPU and interface limits. In comparison, each NASD is able to achieve 6.2 MB/s of the raw 7.5 MB/s available from its underlying dual Medallists. Finally, the NFS line is the one most comparable to the NASD line and shows the bandwidth when all clients read from a single NFS file striped across n disks. This configuration is slower at 20.2 MB/s than NFS-parallel because its prefetching heuristics fail in the presence of multiple request streams to a single file.
In summary, NASD PFS on Cheops delivers nearly all of the bandwidth of the NASD drives, while the same application using a powerful NFS server fails to deliver half the performance of the underlying Cheetah drives.