NASD: Cheops Overview
Network-attached secure disks (NASDs) exploit switched networks to offer scalable storage by moving the file server off the storage access path, reducing its function to an off-line, name-mapping access authorization service, allowing clients to directly access NASD devices. Traditionally, network shared services and abstractions are provided by layering services on shared machines (e.g. a web server above a file server above a RAID controller) with each server inducing a store-and-forward data copy and a synchronous serialization point. While this type of layering simplifies implementation because of centralized state, it creates a performance and scalability bottleneck and adds substantial cost to the system.
Research on Cheops focuses on the problem of providing an enhanced storage service on top of NASDs offering RAID, storage migration and load balanced allocation without reintroducing synchronous shared servers.
The focus of the research is to investigate the architecture, protocols and the NASD support required to enable such decentralized scalable operation. In particular, the goal is to define and implement NASD support, thus enabling scalable storage service (in particular scalable synchronization), as well as algorithms to provide object migration, allocation, and load balancing with high scalability.
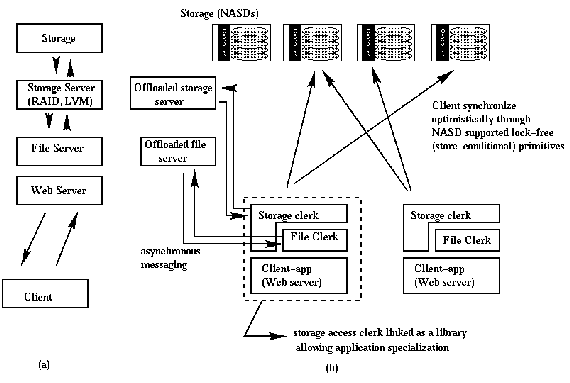
This figure contrasts a traditional layered model where client requests travel through a stack of abstractions implemented at the server machine (a) to a decomposed model in the Cheops/NASD where clients implement most of the resource intensive operations locally (at the local storage clerk) (b).
Cheops involves clients in the implementation of enhanced storage abstractions to ensure scalability. However, by virtue of its design, client involvement in Cheops does not compromise security. Furthermore, to achieve true scalability, Cheops does not require global synchronization protocols across clients.
For instance, synchronization is distributed so that there is no single
synchronization point. Instead, the NASD that stores the data handles
the synchronization concerning that data. Clients operate in a loosely
coupled fashion, and synchronize optimistically at the NASD drive when
they access the data.
Results
So far, the following areas in Cheops are showing promising results:- Optimistic concurrency control for shared storage: We developed
protocols that enabled multiple clients to access shared storage in
a "serializable" and "tri-state atomic" fashion without lock messaging.
Our protocols have been shown to reduce latency by a factor of 2 or
more, depending on the degree of contention in the workload. Throughput
has also been substantially improved over that achieved via traditional
(stripe) locking protocols. Our work on optimistic concurrency control
enables a highly concurrent shared (multi-host) RAID implementation
without stripe locking. Another important application of the protocols
is in ensuring tri-state atomicity for large (multi-block, multi-device)
updates without two phase locking and with minimal extra processing.
Tri-state atomicity means that a large update either completes in
its entirety, does not modify any of the blocks, or partially completes
in a detectable fashion on later reads.
- User-level storage access: We have implemented Cheops (clerk) as
a user level library to enable storage access without kernel intervention.
The library acquires capabilities from the Cheops storage manager
and does not need the local kernel for access control (since the NASD
across the network does not trust the machine's kernel anyway and
requires capabilities cryptographically sealed by the storage manager
before allowing access). The user level implementation of Cheops exploits
the low latency of virtualized network interface technologies such
as VIA. Cluster applications can not only perform application messaging
but also storage access from the user-level at low latencies and without
kernel overhead.
- Linear scalable bandwidth: We recently demonstrated that data intensive applications, such as mining massive transaction record databases, can receive a scalable bandwidth of 7MB/sec per NASD drive up to 14 drives, for a total aggregate bandwidth of about 100MB/sec.