DiskReduce: RAIDing the Cloud
 |
||
| Replication is used in GFS/HDFS to tolerate failures, with high storage overhead. | RAID encoding helps reduce storage overhead. | |
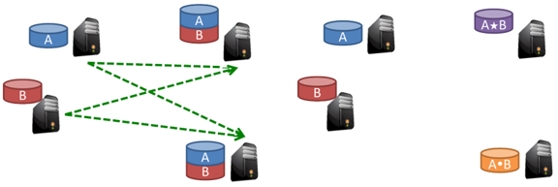
The first generation of Data-Intensive Scalable Computing file systems employed only replication for reliability, typically delivering users with only about a third of the storage capacity of the raw disks. In this project, we investigate DiskReduce, a framework for integrating RAID into these replicated storage systems to lower storage capacity overhead, for example, from 200% to 25% when triplicated data is dynamically replaced with 8+2 RAID 6 encoding.
Based on data collected from Yahoo! and Facebook, we model the capacity effectiveness of simple and not so simple strategies for grouping data blocks into RAID sets; the most capacity efficient strategies suffer from "small write penalties" we ameliorate with deferred deletion. Because replication is intuitively stronger than common RAID erasure codes, we construct a data reliability model, apply it to scales similar to our collected data and explore the tradeoff between capacity and reliability.
Replacing triplication with RAID 6 protects against all double failures in both cases, but most would expect triplication to be a stronger code. We employ a renewal reward Markov model to measure the expected annual data loss. Triplication is stronger as measured by estimated annual data loss, but this loss rate pale comapred to other sources of data loss such as human errors. The time needed to detect failures turns out to be a key parameter because it bounds the benefit of parallel repair, tolerating slower background repair and forcing larger systems to lose more data annually. Moreover, if faster failure detection causes more false positive failures the net effect can be more data loss than with slower more precise failure detection.
Prototype
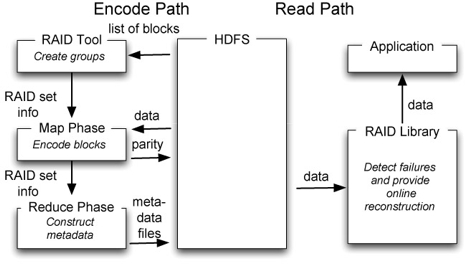
Our published DiskReduce implementation is built as a tool and a library layered on top of and independent of HDFS. This tool can encode directories into RAID sets and repair corrupted files, and the library can detect and correct missing data while reading. Without comments, the tool and library consist of less than 2,700 lines of Java code including RAID 6 code based on the open-source Jerasure coding library. This implementation is available via MAPREDUCE-2036 and is expected to be released with Hadoop 0.22.
People
FACULTY
Garth Gibson
GRADUATE STUDENTS
Bin Fan
Wittawat Tantisiriroj
Lin Xiao
Publications
- DiskReduce: RAID for Data-Intensive Scalable Computing. Bin Fan, Wittawat Tantisiriroj, Lin Xiao, Garth Gibson. PDSW 09 (4th Petascale Data Storage Workshop Supercomputing '09).
Abstract / PDF [304K]
Presentations
- DiskReduce: RAID for Data-Intensive Scalable Computing. Bin Fan, Wittawat Tantisiriroj, Lin Xiao, Garth Gibson. PDSW 09 (4th Petascale Data Storage Workshop Supercomputing '09).
PDF
- DiskReduce: RAIDing the Cloud. Bin Fan, Wittawat Tantisiriroj, Lin Xiao, and Garth Gibson. WIP FAST. Feb. 2010.
PDF
- DiskReduce v2.0 for HDFS. Garth Gibson, Bin Fan, Wittawat Tantisiriroj, Lin Xiao. Open Cirrus Summit, Jan 28, 2010.
PDF
Acknowledgements
We would like to thank Robert Chansler, Raj Merchia and Hong Tang from Yahoo! for providing various help and Dhruba Borthakur from Facebook for providing statistics and feedback. The work in this paper is based on research supported in part by the Betty and Gordon Moore Foundation, by the Department of Energy, under award number DE-FC02-06ER25767, by the Los Alamos National Laboratory, under contract number 54515-001-07, by the National Science Foundation under awards CCF-1019104, OCI-0852543, CNS-0546551 and SCI-0430781, and by Google and Yahoo! research awards.
We thank the members and companies of the PDL Consortium: Amazon, Bloomberg LP, Datadog, Google, Honda, Intel Corporation, Jane Street, LayerZero Research, Meta, Microsoft Research, Oracle Corporation, Oracle Cloud Infrastructure, Pure Storage, Salesforce, Samsung Semiconductor Inc., and Western Digital for their interest, insights, feedback, and support.