Attribute-Based Learning Environments (ABLE)
Extended Overview
The file system community has suggested that hints about a file's access pattern, size, and lifespan can aid in a variety of ways including improving the file's layout on disk and increasing the effectiveness of prefetching and caching. Unfortunately, earlier hint-based schemes have required the application designer or programmer to supply explicit hints using a process that is both tedious and error-prone, or to use a special compiler that can recognize specific I/O patterns and automatically insert hints. Neither of these schemes have been widely adopted.
Applications already give useful hints to the
file system, in the form of file attributes, and the file system
can successfully predict many file properties from these hints.
A file's attributes (file name, uid, gid, mode) are, to some
extent, associated with its long term properties (size, lifespan,
and access pattern) and this fact suggests that these associations
can be used to make predictions on the properties of a file
at creation time.
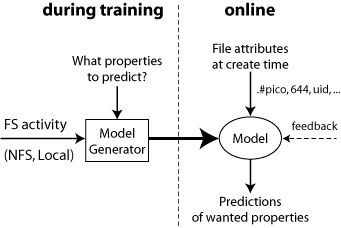 |
|
Using file attributes to predict file properties. During the training period a predictor for file properties (i.e., lifespan, size, and access pattern) is constructed from observations of file system activity. The file system can then use this model to predict the properties of newly-created files.
|
To investigate the possibility of creating a predictive model from file trace data, we constructed an Attribute-Based Learning Environment (ABLE) to evaluate the predictive power of file attributes. The input to ABLE is a table of information about files whose attributes and properties we have already observed and a list of properties for which we wish to predict. The output is a statistical analysis of the sample, a chi-squared ranking of each file attribute relative to each property, and a collection of predictive models that can be used to make predictions about new files.
The ABLE process consists of three steps:- Obtaining Training Data. Obtain a sample of files and for each file record its attributes (name, uid, gid, mode) and properties (size, lifespan, and access pattern).
- Constructing a Predictive Classifier. For each file property, we train a learning algorithm to classify each file in the training data according to that property. The result of this step is a set of predictive models that classifies each file in the training data and can be used to make predictions on newly created files.
- Validating the Model. The model is used to predict the properties of new files, and then check whether the predictions are accurate.
There are many possible uses for such predictions. File cache management policies may benefit if, when choosing a buffer to evict, there was an accurate prediction of whether or not that buffer would be accessed in the near future (or at all). Pre-fetching can also benefit from predictions; if we can identify files that are highly likely to be read sequentially from beginning to end (perhaps on a user-by-user basis), then we can begin pre-fetching blocks for that file as soon as a client opens it. Predictions may also be helpful in optimizing file layout -- if we can predict how large a file will be, and what access patterns the file will experience, then we can pre-allocate space on the disk in order to optimally accommodate these properties.