IndexFS: Scaling File System Metadata Performance
The growing size of modern storage systems is expected to exceed billions of objects, making metadata scalability critical to overall performance. Many existing distributed file systems only focus on providing highly parallel fast access to file data, and lack a scalable metadata service.
We introduce a middleware design called IndexFS that adds support to existing file systems such as PVFS, Lustre, and HDFS for scalable high-performance operations on metadata and small files. IndexFS uses a table-based architecture that incrementally partitions the namespace on a per-directory basis using GIGA+ technique, preserving server and disk locality for small directories. An optimized log-structured layout is used to store metadata and small files efficiently. IndexFS applies two client-based storm-free caching techniques: bulk namespace insertion for creation intensive workloads such as N-N checkpointing; and stateless consistent metadata caching for hot spot mitigation.
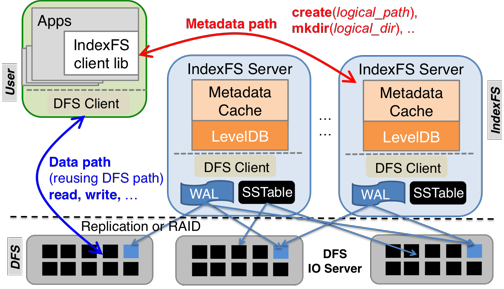
The architecture of IndexFS: middleware layered on top of existing cluster file systems.
By combining these techniques, IndexFS can scale to at least 128 metadata servers, because that is the biggest test we have tried so far. Experiments show our out-of-core metadata throughput out-performing existing solutions such as PVFS, Lustre, and HDFS by 50% to two orders of magnitude.
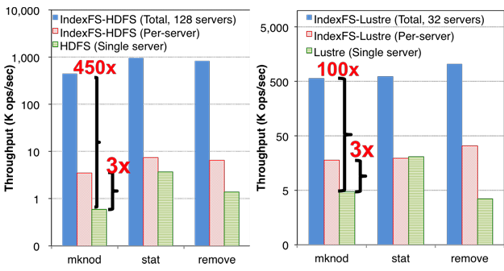
Per-server and aggregated throughput during mdtest with IndexFS layered on top of Lustre
and HDFS on a log scale. HDFS and Lustre have only one metadata server.
People
FACULTY
Garth Gibson
GRAD STUDENTS
Kai Ren
Qing
Zheng
Swapil Patil
Publications
- IndexFS: Scaling File System Metadata Performance with Stateless Caching and Bulk Insertion. Kai Ren, Qing Zheng, Swapnil Patil, Garth Gibson. ACM/IEEE Int'l Conf. for High Performance Computing, Networking, Storage and Analysis (SC'14), November 16-21, 2014, New Orleans, LA.
Abstract / PDF [939K] / Slides [1M]
- BatchFS: Scaling the File System Control Plane with Client-Funded Metadata Servers. Qing Zheng, Kai Ren, Garth Gibson. Proceedings of the 9th international Petascale Data Storage Workshop (PDSW '14) held in conjunction with Supercomputing '14. November 16, 2014, New Orleans, LA.
Abstract / PDF [651K]
- TABLEFS: Enhancing Metadata Efficiency in the Local File System.
Kai Ren, Garth Gibson.
2013 USENIX Annual Technical Conference, June 26-28, 2013, San Jose, CA.
Abstract / PDF [867K]
- A Case for Scaling HPC Metadata Performance through
De-specialization.
Swapnil Patil,
Kai Ren,
Garth Gibson. 7th Petascale Data Storage Workshop held in conjunction with Supercomputing '12, November 12, 2012. Salt Lake City, UT. Supersedes Carnegie Mellon University Parallel Data Lab Technical Report CMU-PDL-12-111, November 2012.
Abstract / PDF [512K]
Software Release
The code is open sourced under PDL license, which is a BSD-style three clause license.
Acknowledgements
We thank Chuck Cranor, Mitch Franzos, Aaron Caldwell, Alfred Torrez and Sage Weil for helping us run and understand experiments on PanFS, PVFS, HDFS, Lustre and Ceph. We thank Brett Kettering, Andy Pavlo and Wolfgang Richter for helpful discussions and comments on this paper. We especially thank Los Alamos National Laboratory for running our software on one of their HPC clusters (Smog), Panasas for providing a storage cluster and LinkedIn for giving us a trace of its HDFS metadata workload. This research was supported in part by the National Science Foundation under awards CNS-1042537 and CNS-1042543 (PRObE, www.nmc-probe.org), the DOE and Los Alamos National Laboratory, under contract number DE-AC52-06NA25396 subcontracts 161465 and 153593 (IRHPIT), the Qatar National Research Foundation, under award 09-1116-1-172, a Symantec research labs graduate fellowship, and Intel as part of the Intel Science and Technology Center for Cloud Computing (ISTC-CC).
We thank the members and companies of the PDL Consortium: Amazon, Bloomberg LP, Datadog, Google, Honda, Intel Corporation, Jane Street, LayerZero Research, Meta, Microsoft Research, Oracle Corporation, Oracle Cloud Infrastructure, Pure Storage, Salesforce, Samsung Semiconductor Inc., and Western Digital for their interest, insights, feedback, and support.