incast
Cluster-based storage systems are becoming an increasingly important target for both research and industry. These storage systems consist of a networked set of smaller storage servers, with data spread across these servers to increase performance and reliability. Building these systems using commodity TCP/IP and Ethernet networks is attractive because of their low cost and ease-of-use, and because of the desire to share the bandwidth of a storage cluster over multiple compute clusters, visualization systems, and personal machines. Furthermore, non-IP storage networking lacks some of the mature capabilities and breadth of services available in IP networks. However, building storage systems on TCP/IP and Ethernet poses several challenges. Our work analyzes one important barrier to high-performance storage over TCP/IP: the Incast problem.
TCP Incast is a catastrophic TCP throughput collapse that occurs as
the number of storage servers sending data to a client increases past
the ability of an Ethernet switch to buffer packets.
In a clustered file system, for example, a client application requests
a data block striped across several storage servers, issuing the next
data block request only when all servers have responded with their
portion (Figure 1). This synchronized request workload
can result in packets overfilling the buffers on the client's port on
the switch, resulting in many losses. Under severe
packet loss, TCP can experience a timeout that lasts a minimum
of 200ms, determined by the TCP minimum retransmission timeout
(RTOmin).
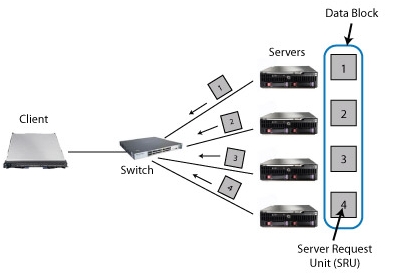
Figure 1: A simple cluster-based storage environment with one client requesting
data from multiple servers through synchronized reads.
When a server involved in a synchronized request experiences a timeout, other servers can finish sending their responses, but the client must wait a minimum of 200ms before receiving the remaining parts of the response, during which the client's link may be completely idle. The resulting throughput seen by the application may be as low as 1-10\% of the client's bandwidth capacity, and the per-request latency will be higher than 200ms (Figure 2).
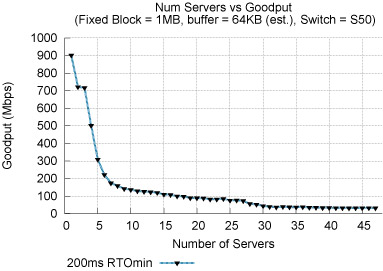
Figure 2: TCP Incast: Throughput collapse for a synchronized reads
application performed on a real storage cluster.
The motivation for solving this problem is the increasing interest in
using Ethernet and TCP for interprocessor communication and bulk
storage transfer applications in the fastest, largest data centers,
instead of Fibrechannel or Infiniband. Provided that TCP adequately
supports high bandwidth, low latency, synchronized and parallel
applications, there is a strong desire to "wire-once" and reuse the
mature, well-understood transport protocols that are so familiar in
lower bandwidth networks.
Solutions
Existing TCP improvements---NewReno, SACK, RED, ECN, Limited Transmit, and modifications to Slow Start---sometimes increase throughput, but do not substantially change the incast-induced throughput collapse (See FAST 2008 paper below). However, we have identified three solutions to the Incast problem.
First, larger switch buffers can delay the onset of Incast (doubling the buffer size doubles the number of servers that can be contacted). But increased switch buffering comes at a substantial dollar cost -- switches with 1MB packet buffering per port may cost as much as $500,000. Second, Ethernet flow control is effective when the machines are on a single switch, but is dangerous across inter-switch trunks because of head-of-line blocking.
Finally, reducing TCP's minimum RTO allows nodes
to maintain high throughput with several times as many nodes. We find
that providing microsecond resolution TCP retransmissions can
achieve full throughput for as many as 47 servers in a real world cluster environment (Figure 3).
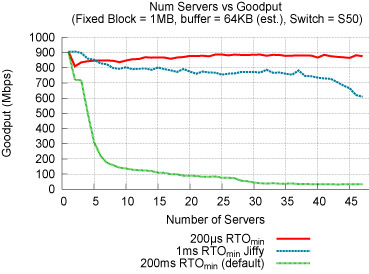
Figure 3: Reducing RTO to microsecond granularity alleviates Incast for up
to 47 concurrent senders. Measurements taken on 48 Linux 2.6.28 nodes,
all attached to a single switch.
People
FACULTY
David Andersen
Greg Ganger
Garth Gibson
Srini Seshan
Michael Stroucken
STUDENTSElie Krevat
Amar Phanishayee
Hiral Shah
Wittawat Tantisiriroj
Vijay Vasudevan
Publications
- Safe and Effective Fine-grained TCP Retransmissions for Datacenter Communication. Vijay Vasudevan, Amar Phanishayee, Hiral Shah, Elie Krevat, David G. Andersen, Gregory R. Ganger, Garth A. Gibson, Brian Mueller. SIGCOMM’09, August 17–21, 2009, Barcelona, Spain. Supercedes Carnegie Mellon University Parallel Data Lab Technical Report CMU-PDL-09-101, Feb. 2009.
Abstract / PDF [755K]
- Incast Kernel Patch. Download the patch to enable high-resolution TCP retransmissions at http://www.cs.cmu.edu/~vrv/incast/.
- Solving TCP Incast in Cluster Storage Systems. Vijay Vasudevan, Hiral Shah, Amar Phanishayee, Elie Krevat, David Andersen, Greg Ganger, Garth Gibson. FAST 2009 Work in Progress Report. 7th USENIX Conference on File and Storage Technologies. Feb 24-27, 2009, San Francisco, CA.
PDF [70K]
- A (In)Cast of Thousands: Scaling Datacenter TCP to Kiloservers and Gigabits. Vijay Vasudevan, Amar Phanishayee, Hiral Shah, Elie Krevat,
David G. Andersen, Gregory R. Ganger, Garth A. Gibson.
Carnegie Mellon University Parallel Data Lab Technical Report CMU-PDL-09-101, Feb. 2009. Superceded by SIGCOMM'09: "Safe and Effective Fine-grained TCP Retransmissions for Datacenter Communication."
Abstact / PDF [317K]
- Measurement and Analysis of TCP Throughput Collapse in Cluster-based Storage Systems. Amar Phanishayee, Elie Krevat, Vijay Vasudevan, David G. Andersen, Gregory R. Ganger, Garth A. Gibson, Srinivasan Seshan. 6th USENIX Conference on File and Storage Technologies (FAST '08). Feb. 26-29, 2008. San Jose, CA. Supercedes Carnegie Mellon University Parallel Data Lab Technical Report CMU-PDL-07-105, September 2007.
Abstract / PDF [374K]
- On Application-level Approaches to Avoiding TCP Throughput Collapse in Cluster-Based Storage Systems. E. Krevat, V. Vasudevan, A. Phanishayee, D. Andersen, G. Ganger, G. Gibson, S. Seshan. Proceedings of the 2nd international Petascale Data Storage Workshop (PDSW '07)
held in conjunction with Supercomputing '07. November 11, 2007, Reno, NV.
Abstract / PDF [124K]
Code
- https://github.com/amarp/Incast This is the distribution containing source files and scripts corresponding to the project investigating TCP Throughput Collapse in Cluster-Based Storage Systems. For an overview of the
project, please refer to our FAST 2008 paper entitled "Measurement and Analysis of TCP Throughput Collapse in Cluster-Based Storage Systems".
Related Items
- Berkeley WREN 2009
- MSR SIGCOMM 2010: DCTCP paper mentioning Microsoft Bing services affected by incast
- MSR Conext 2010
- Jeff Dean SOCC Keynote, slide 55-56
- The CoNext best paper award this year was given to: "ICTCP: Incast Congestion Control for TCP in Data Center Networks" (Microsoft)
Acknowledgements
We thank the members and companies of the PDL Consortium: Bloomberg LP, Everpure, Google, Jane Street, LayerZero Labs, Meta, Microsoft Research, Oracle Corporation, Salesforce, Uber, and Western Digital for their interest, insights, feedback, and support.