YCSB++
In today's cloud computing world, we have seen an explosion in the number of cloud table stores developed for serving cloud data. These table stores are typically designed for high scalablility by using semi-structured data format and weak semantics, and optimized for different priorities such as query speed, ingest speed, availability, and interactivity. Further, as these systems mature, lots of adavanced features, such as ingest speed-up techniques and function shipping filters from client to servers, have been developed to serve a wide range of applications and workloads.
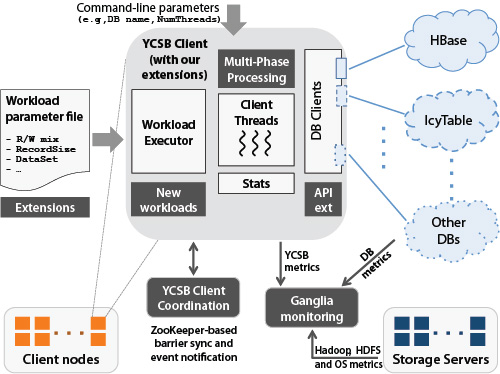
YCSB++ functionality testing framework – Light colored boxes show modules in
YCSB v0.1.3 and dark shaded boxes show our new extensions.
To understand the trade-offs between systems and debug the performance of these advanced features, we developed an advanced benchmark suite YCSB++ that goes beyond measuring the rate of simple workloads. YCSB++ is built on top of the Yahoo! Cloud Serving Benchmark (YCSB) with a set of extensions to improve performance understanding and debugging of these advanced features.
- Parallel testing using multiple YCSB client node ZooKeeper-based barrier synchronization for multiple YCSB clients to coordinate start and end of different tests.
- Weak consistency testing Table stores provide high throughput and high availability by eliminating expensive features, particularly the strong consistency found in traditional databases. Systems may offer "loose" or "weak" consistency semantics, such as eventual consistency. In YCSB++, we implemented distributed event notification using ZooKeeper to understand the cost (measured as read-after-write latency) of weak consistency.
- Bulk-load testing To efficiently insert massive data-sets, various table stores rely on specialized, high-throughput tools and interfaces. For example, both HBase and Accumulo support to directly load data files with the format native to table stores. YCSB++ provides an external Hadoop tool that formats data to be inserted into a format used natively by the table store servers.
- Table pre-splitting for fast ingest Many scalable table stores distribute a table over multiple servers. Each server stores a range of keys, and the range changes when the server overflows to split into two tablets. These split operations limit the performance of ingest-intensive workloads. One way to reduce this splitting overhead is called "pre-splitting", which is to split a table when it is empty or small into multiple key ranges based on a priori knowledge. A new workload executor is implemented for testing the effectiveness of pre-splitting. It can externally pre-split the key space into variable-sized and fixed-size ranges.
- Server-side filtering Server-side filtering offloads compute from the client to the server, possibly reducing the amount of data transmitted over the network and amount of data fetched from disk. In YCSB++, new workload executor is implemented which can generate "deterministic" data to allow use of appropriate filters and DB client API extensions are also provided to send filters to servers.
- Access control New workload generator and API extensions to DB clients to test both schema-level and cell-level access control models
- Integration with monitoring tool We customized an existing cluster monitoring tool Otus to gather the internal statistics of YCSB++, table stores, system services like HDFS, and operating systems, and to offer easy post-test correlation and reporting of performance behaviors.
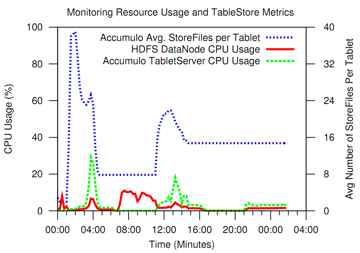
An example of combining different logical aggregates
in Otus graphs.
Scalable Stores Supported by YCSB++
Code Distribution
People
FACULTY
Garth Gibson
Julio López
GRAD STUDENTS
Swapnil Patil
Kai Ren
Wittawat Tantisiririoj
Lin Xiao
Publications
- YCSB++: Benchmarking and Performance Debugging Advanced Features in Scalable Table Stores. Swapnil Patil, Milo Polte, Kai Ren, Wittawat Tantisiriroj, Lin Xiao, Julio Lopez, Garth Gibson, Adam Fuchs, Billie Rinaldi. Proc. of the 2nd ACM Symposium on Cloud Computing (SOCC '11), October 27–28, 2011, Cascais, Portugal. Supersedes Carnegie Mellon University Parallel Data Laboratory Technical Report CMU-PDL-11-111, August 2011.
Abstract / PDF [1.2M]
Acknowledgements
We thank the members and companies of the PDL Consortium: Amazon, Google, Hitachi Ltd., Honda, Intel Corporation, IBM, Meta, Microsoft Research, Oracle Corporation, Pure Storage, Salesforce, Samsung Semiconductor Inc., Two Sigma, and Western Digital for their interest, insights, feedback, and support.